
Commit
·
c176aea
0
Parent(s):
ic
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- A6 - 1.png +0 -0
- Isp.png +0 -0
- PINN/__init__.py +0 -0
- PINN/__pycache__/__init__.cpython-310.pyc +0 -0
- PINN/__pycache__/pinns.cpython-310.pyc +0 -0
- PINN/pinns.py +53 -0
- README.md +13 -0
- TDP.png +0 -0
- TPU.png +0 -0
- Tisp.png +0 -0
- Unknown-3.jpg +0 -0
- ann.png +0 -0
- app.py +83 -0
- bb.md +38 -0
- dH.png +0 -0
- dT.png +0 -0
- dashboard.png +0 -0
- data/bound.pkl +0 -0
- data/dataset.csv +24 -0
- data/dataset.pkl +0 -0
- data/new +0 -0
- data/test.pkl +0 -0
- disc.png +0 -0
- docs/.DS_Store +0 -0
- docs/main.html +106 -0
- fig1.png +0 -0
- gan.png +0 -0
- gen.png +0 -0
- geom.png +0 -0
- graph.jpg +0 -0
- intro.md +453 -0
- invariant.png +0 -0
- maT.png +0 -0
- main.md +1060 -0
- main.py +83 -0
- model.png +0 -0
- models/model.onnx +0 -0
- module_name.md +456 -0
- nets/__init__.py +0 -0
- nets/__pycache__/HET_dense.cpython-310.pyc +0 -0
- nets/__pycache__/__init__.cpython-310.pyc +0 -0
- nets/__pycache__/deep_dense.cpython-310.pyc +0 -0
- nets/__pycache__/dense.cpython-310.pyc +0 -0
- nets/__pycache__/design.cpython-310.pyc +0 -0
- nets/__pycache__/envs.cpython-310.pyc +0 -0
- nets/deep_dense.py +32 -0
- nets/dense.py +27 -0
- nets/design.py +42 -0
- nets/envs.py +491 -0
- nets/opti/__init__.py +0 -0
A6 - 1.png
ADDED

|
Isp.png
ADDED

|
PINN/__init__.py
ADDED
|
File without changes
|
PINN/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (140 Bytes). View file
|
|
|
PINN/__pycache__/pinns.cpython-310.pyc
ADDED
|
Binary file (1.76 kB). View file
|
|
|
PINN/pinns.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn,tensor
|
| 2 |
+
import numpy as np
|
| 3 |
+
import seaborn as sns
|
| 4 |
+
class PINNd_p(nn.Module):
|
| 5 |
+
""" $d \mapsto P$
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
def __init__(self):
|
| 10 |
+
super(PINNd_p,self).__init__()
|
| 11 |
+
weights = tensor([60.,0.5])
|
| 12 |
+
self.weights = nn.Parameter(weights)
|
| 13 |
+
def forward(self,x):
|
| 14 |
+
|
| 15 |
+
c,b = self.weights
|
| 16 |
+
x1 = (x[0]/(c*x[1]))**0.5
|
| 17 |
+
return x1
|
| 18 |
+
|
| 19 |
+
class PINNhd_ma(nn.Module):
|
| 20 |
+
""" $h,d \mapsto m_a $
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
"""
|
| 24 |
+
def __init__(self):
|
| 25 |
+
super(PINNhd_ma,self).__init__()
|
| 26 |
+
weights = tensor([0.01])
|
| 27 |
+
self.weights = nn.Parameter(weights)
|
| 28 |
+
def forward(self,x):
|
| 29 |
+
c, = self.weights
|
| 30 |
+
x1 = c*x[0]*x[1]
|
| 31 |
+
return x1
|
| 32 |
+
|
| 33 |
+
class PINNT_ma(nn.Module):
|
| 34 |
+
"""$ m_a, U \mapsto T$
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
"""
|
| 38 |
+
def __init__(self):
|
| 39 |
+
super(PINNT_ma,self).__init__()
|
| 40 |
+
weights = tensor([0.01])
|
| 41 |
+
self.weights = nn.Parameter(weights)
|
| 42 |
+
def forward(self,x):
|
| 43 |
+
c, = self.weights
|
| 44 |
+
x1 = c*x[0]*x[1]**0.5
|
| 45 |
+
return x1
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Hetfit
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: yellow
|
| 5 |
+
colorTo: blue
|
| 6 |
+
sdk: streamlit
|
| 7 |
+
sdk_version: 1.17.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: cc-by-nc-4.0
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
TDP.png
ADDED

|
TPU.png
ADDED
|
Tisp.png
ADDED

|
Unknown-3.jpg
ADDED

|
ann.png
ADDED

|
app.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
from nets.envs import SCI
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
st.set_page_config(
|
| 7 |
+
page_title="HET_sci",
|
| 8 |
+
menu_items={
|
| 9 |
+
'About':'https://advpropsys.github.io'
|
| 10 |
+
}
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
st.title('HETfit_scientific')
|
| 14 |
+
st.markdown("#### Imagine a package which was engineered primarly for data driven plasma physics devices design, mainly low power hall effect thrusters, yup that's it"
|
| 15 |
+
"\n### :orange[Don't be scared away though, it has much simpler interface than anything you ever used for such designs]")
|
| 16 |
+
st.markdown('### Main concepts:')
|
| 17 |
+
st.markdown( "- Each observational/design session is called an **environment**, for now it can be either RCI or SCI (Real or scaled interface)"
|
| 18 |
+
"\n In this overview we will only touch SCI, since RCI is using PINNs which are different topic"
|
| 19 |
+
"\n- You specify most of the run parameters on this object init, :orange[**including generation of new samples**] via GAN"
|
| 20 |
+
"\n- You may want to generate new features, do it !"
|
| 21 |
+
"\n- Want to select best features for more effctive work? Done!"
|
| 22 |
+
"\n- Compile environment with your model of choice, can be ***any*** torch model or sklearn one"
|
| 23 |
+
"\n- Train !"
|
| 24 |
+
"\n- Plot, inference, save, export to jit/onnx, measure performance - **they all are one liners** "
|
| 25 |
+
)
|
| 26 |
+
st.markdown('### tl;dr \n- Create environment'
|
| 27 |
+
'\n```run = SCI(*args,**kwargs)```'
|
| 28 |
+
'\n - Generate features ```run.feature_gen()``` '
|
| 29 |
+
'\n - Select features ```run.feature_importance()```'
|
| 30 |
+
'\n - Compile env ```run.compile()```'
|
| 31 |
+
'\n - Train model in env ```run.train()```'
|
| 32 |
+
'\n - Inference, plot, performance, ex. ```run.plot3d()```'
|
| 33 |
+
'\n #### And yes, it all will work even without any additional arguments from user besides column indexes'
|
| 34 |
+
)
|
| 35 |
+
st.write('Comparison with *arXiv:2206.04440v3*')
|
| 36 |
+
col1, col2 = st.columns(2)
|
| 37 |
+
col1.metric('Geometry accuracy on domain',value='83%',delta='15%')
|
| 38 |
+
col2.metric('$d \mapsto h$ prediction',value='98%',delta='14%')
|
| 39 |
+
|
| 40 |
+
st.header('Example:')
|
| 41 |
+
|
| 42 |
+
st.markdown('Remeber indexes and column names on this example: $P$ - 1, $d$ - 3, $h$ - 3, $m_a$ - 6,$T$ - 7')
|
| 43 |
+
st.code('run = SCI(*args,**kwargs)')
|
| 44 |
+
|
| 45 |
+
run = SCI()
|
| 46 |
+
st.code('run.feature_gen()')
|
| 47 |
+
run.feature_gen()
|
| 48 |
+
st.write('New features: (index-0:22 original samples, else is GAN generated)',run.df.iloc[1:,9:].astype(float))
|
| 49 |
+
st.write('Most of real dataset is from *doi:0.2514/1.B37424*, hence the results mostly agree with it in specific')
|
| 50 |
+
st.code('run.feature_importance(run.df.iloc[1:,1:7].astype(float),run.df.iloc[1:,7]) # Clear and easy example')
|
| 51 |
+
|
| 52 |
+
st.write(run.feature_importance(run.df.iloc[1:,1:6].astype(float),run.df.iloc[1:,6]))
|
| 53 |
+
st.markdown(' As we can see only $h$ and $d$ passed for $m_a$ model, not only that linear dependacy was proven experimantally, but now we got this from data driven source')
|
| 54 |
+
st.code('run.compile(idx=(1,3,7))')
|
| 55 |
+
run.compile(idx=(1,3,7))
|
| 56 |
+
st.code('run.train(epochs=10)')
|
| 57 |
+
if st.button('Start Training⏳',use_container_width=True):
|
| 58 |
+
run.train(epochs=10)
|
| 59 |
+
st.code('run.plot3d()')
|
| 60 |
+
st.write(run.plot3d())
|
| 61 |
+
st.code('run.performance()')
|
| 62 |
+
st.write(run.performance())
|
| 63 |
+
else:
|
| 64 |
+
st.markdown('#')
|
| 65 |
+
|
| 66 |
+
st.markdown('---\nTry it out yourself! Select a column from 1 to 10')
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
number = st.number_input('Here',min_value=1, max_value=10, step=1)
|
| 70 |
+
|
| 71 |
+
if number:
|
| 72 |
+
if st.button('Compile And Train💅',use_container_width=True):
|
| 73 |
+
st.code(f'run.compile(idx=(1,3,{number}))')
|
| 74 |
+
run.compile(idx=(1,3,number))
|
| 75 |
+
st.code('run.train(epochs=10)')
|
| 76 |
+
run.train(epochs=10)
|
| 77 |
+
st.code('run.plot3d()')
|
| 78 |
+
st.write(run.plot3d())
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
st.markdown('In this intro we covered simplest userflow while using HETFit package, resulted data can be used to leverage PINN and analytical models of Hall effect thrusters'
|
| 83 |
+
'\n #### :orange[To cite please contact author on https://github.com/advpropsys]')
|
bb.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<a id="nets.opti.blackbox"></a>
|
| 2 |
+
|
| 3 |
+
# :orange[Hyper Paramaters Optimization class]
|
| 4 |
+
## nets.opti.blackbox
|
| 5 |
+
|
| 6 |
+
<a id="nets.opti.blackbox.Hyper"></a>
|
| 7 |
+
|
| 8 |
+
### Hyper Objects
|
| 9 |
+
|
| 10 |
+
```python
|
| 11 |
+
class Hyper(SCI)
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
Hyper parameter tunning class. Allows to generate best NN architecture for task. Inputs are column indexes. idx[-1] is targeted value.
|
| 15 |
+
|
| 16 |
+
<a id="nets.opti.blackbox.Hyper.start_study"></a>
|
| 17 |
+
|
| 18 |
+
#### start\_study
|
| 19 |
+
|
| 20 |
+
```python
|
| 21 |
+
def start_study(n_trials: int = 100,
|
| 22 |
+
neptune_project: str = None,
|
| 23 |
+
neptune_api: str = None)
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
Starts study. Optionally provide your neptune repo and token for report generation.
|
| 27 |
+
|
| 28 |
+
**Arguments**:
|
| 29 |
+
|
| 30 |
+
- `n_trials` _int, optional_ - Number of iterations. Defaults to 100.
|
| 31 |
+
- `neptune_project` _str, optional_ - None
|
| 32 |
+
- neptune_api (str, optional):. Defaults to None.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
**Returns**:
|
| 36 |
+
|
| 37 |
+
- `dict` - quick report of results
|
| 38 |
+
|
dH.png
ADDED
|
dT.png
ADDED

|
dashboard.png
ADDED

|
data/bound.pkl
ADDED
|
Binary file (34 kB). View file
|
|
|
data/dataset.csv
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Name,U,d,h,j,Isp,nu_t,T,m_a
|
| 2 |
+
SPT-20 [21],52.4,180,15.0,5.0,32.0,0.47,3.9,839
|
| 3 |
+
SPT-25 [22],134,180,20.0,5.0,10,0.59,5.5,948
|
| 4 |
+
HET-100 [23],174,300,23.5,5.5,14.5,0.50,6.8,1386
|
| 5 |
+
KHT-40 [24],187,325,31.0,9.0,25.5,0.69,10.3,1519
|
| 6 |
+
KHT-50 [24],193,250,42.0,8.0,25.0,0.88,11.6,1339
|
| 7 |
+
HEPS-200,195,250,42.5,8.5,25.0,0.88,11.2,1300
|
| 8 |
+
BHT-200 [2526],200,250,21.0,5.6,11.2,0.94,12.8,1390
|
| 9 |
+
KM-32 [27],215,250,32.0,7.0,16.0,1.00,12.2,1244
|
| 10 |
+
SPT-50M [28],245,200,39.0,11.0,25.0,1.50,16.0,1088
|
| 11 |
+
SPT-30 [23],258,250,24.0,6.0,11.0,0.98,13.2,1234
|
| 12 |
+
KM-37 [29],283,292,37.0,9.0,17.5,1.15,18.5,1640
|
| 13 |
+
CAM200 [3031],304,275,43.0,12.0,24,1.09,17.3,1587
|
| 14 |
+
SPT-50 [21],317,300,39.0,11.0,25.0,1.18,17.5,1746
|
| 15 |
+
A-3 [21],324,300,47.0,13.0,30.0,1.18,18.0,1821
|
| 16 |
+
HEPS-500,482,300,49.5,15.5,25.0,1.67,25.9,1587
|
| 17 |
+
BHT-600 [2632],615,300,56.0,16.0,32,2.60,39.1,1530
|
| 18 |
+
SPT-70 [33],660,300,56.0,14.0,25.0,2.56,40.0,1593
|
| 19 |
+
SPT-100 [934],1350,300,85.0,15.0,25.0,5.14,81.6,1540
|
| 20 |
+
UAH-78AM,520,260,78.0,20,40,2,30,1450
|
| 21 |
+
MaSMi40,330,300,40,6.28,12.56,1.5,13,1100
|
| 22 |
+
MaSMi60,700,250,60,9.42,19,2.56,30,1300
|
| 23 |
+
MaSMiDm,1000,500,67,10.5,21,3,53,1940
|
| 24 |
+
Music-si,140,288,18,2,6.5,0.44,4.2,850
|
data/dataset.pkl
ADDED
|
Binary file (106 kB). View file
|
|
|
data/new
ADDED
|
Binary file (84.1 kB). View file
|
|
|
data/test.pkl
ADDED
|
Binary file (84.2 kB). View file
|
|
|
disc.png
ADDED

|
docs/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
docs/main.html
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<meta http-equiv="content-type" content="text/html;charset=utf-8">
|
| 5 |
+
<title>main.py</title>
|
| 6 |
+
<link rel="stylesheet" href="pycco.css">
|
| 7 |
+
</head>
|
| 8 |
+
<body>
|
| 9 |
+
<div id='container'>
|
| 10 |
+
<div id="background"></div>
|
| 11 |
+
<div class='section'>
|
| 12 |
+
<div class='docs'><h1>main.py</h1></div>
|
| 13 |
+
</div>
|
| 14 |
+
<div class='clearall'>
|
| 15 |
+
<div class='section' id='section-0'>
|
| 16 |
+
<div class='docs'>
|
| 17 |
+
<div class='octowrap'>
|
| 18 |
+
<a class='octothorpe' href='#section-0'>#</a>
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
</div>
|
| 22 |
+
<div class='code'>
|
| 23 |
+
<div class="highlight"><pre><span></span><span class="kn">import</span> <span class="nn">streamlit</span> <span class="k">as</span> <span class="nn">st</span>
|
| 24 |
+
|
| 25 |
+
<span class="kn">from</span> <span class="nn">nets.envs</span> <span class="kn">import</span> <span class="n">SCI</span>
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
<span class="n">st</span><span class="o">.</span><span class="n">set_page_config</span><span class="p">(</span>
|
| 29 |
+
<span class="n">page_title</span><span class="o">=</span><span class="s2">"HET_sci"</span><span class="p">,</span>
|
| 30 |
+
<span class="n">menu_items</span><span class="o">=</span><span class="p">{</span>
|
| 31 |
+
<span class="s1">'About'</span><span class="p">:</span><span class="s1">'https://advpropsys.github.io'</span>
|
| 32 |
+
<span class="p">}</span>
|
| 33 |
+
<span class="p">)</span>
|
| 34 |
+
|
| 35 |
+
<span class="n">st</span><span class="o">.</span><span class="n">title</span><span class="p">(</span><span class="s1">'HETfit_scientific'</span><span class="p">)</span>
|
| 36 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span><span class="s2">"#### Imagine a package which was engineered primarly for data driven plasma physics devices design, mainly hall effect thrusters, yup that's it"</span>
|
| 37 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">### :orange[Don't be scared away though, it has much simpler interface than anything you ever used for such designs]"</span><span class="p">)</span>
|
| 38 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span><span class="s1">'### Main concepts:'</span><span class="p">)</span>
|
| 39 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span> <span class="s2">"- Each observational/design session is called an **environment**, for now it can be either RCI or SCI (Real or scaled interface)"</span>
|
| 40 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2"> In this overview we will only touch SCI, since RCI is using PINNs which are different topic"</span>
|
| 41 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">- You specify most of the run parameters on this object init, :orange[**including generation of new samples**] via GAN"</span>
|
| 42 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">- You may want to generate new features, do it !"</span>
|
| 43 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">- Want to select best features for more effctive work? Done!"</span>
|
| 44 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">- Compile environment with your model of choice, can be ***any*** torch model or sklearn one"</span>
|
| 45 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">- Train !"</span>
|
| 46 |
+
<span class="s2">"</span><span class="se">\n</span><span class="s2">- Plot, inference, save, export to jit/onnx, measure performance - **they all are one liners** "</span>
|
| 47 |
+
<span class="p">)</span>
|
| 48 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span><span class="s1">'### tl;dr </span><span class="se">\n</span><span class="s1">- Create environment'</span>
|
| 49 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1">```run = SCI(*args,**kwargs)```'</span>
|
| 50 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> - Generate features ```run.feature_gen()``` '</span>
|
| 51 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> - Select features ```run.feature_importance()```'</span>
|
| 52 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> - Compile env ```run.compile()```'</span>
|
| 53 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> - Train model in env ```run.train()```'</span>
|
| 54 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> - Inference, plot, performance, ex. ```run.plot3d()```'</span>
|
| 55 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> #### And yes, it all will work even without any additional arguments from user besides column indexes'</span>
|
| 56 |
+
<span class="p">)</span>
|
| 57 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s1">'Comparison with *arXiv:2206.04440v3*'</span><span class="p">)</span>
|
| 58 |
+
<span class="n">col1</span><span class="p">,</span> <span class="n">col2</span> <span class="o">=</span> <span class="n">st</span><span class="o">.</span><span class="n">columns</span><span class="p">(</span><span class="mi">2</span><span class="p">)</span>
|
| 59 |
+
<span class="n">col1</span><span class="o">.</span><span class="n">metric</span><span class="p">(</span><span class="s1">'Geometry accuracy on domain'</span><span class="p">,</span><span class="n">value</span><span class="o">=</span><span class="s1">'83%'</span><span class="p">,</span><span class="n">delta</span><span class="o">=</span><span class="s1">'15%'</span><span class="p">)</span>
|
| 60 |
+
<span class="n">col2</span><span class="o">.</span><span class="n">metric</span><span class="p">(</span><span class="s1">'$d \mapsto h$ prediction'</span><span class="p">,</span><span class="n">value</span><span class="o">=</span><span class="s1">'98%'</span><span class="p">,</span><span class="n">delta</span><span class="o">=</span><span class="s1">'14%'</span><span class="p">)</span>
|
| 61 |
+
|
| 62 |
+
<span class="n">st</span><span class="o">.</span><span class="n">header</span><span class="p">(</span><span class="s1">'Example:'</span><span class="p">)</span>
|
| 63 |
+
|
| 64 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span><span class="s1">'Remeber indexes and column names on this example: $P$ - 1, $d$ - 3, $h$ - 3, $m_a$ - 6,$T$ - 7'</span><span class="p">)</span>
|
| 65 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run = SCI(*args,**kwargs)'</span><span class="p">)</span>
|
| 66 |
+
|
| 67 |
+
<span class="n">run</span> <span class="o">=</span> <span class="n">SCI</span><span class="p">()</span>
|
| 68 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.feature_gen()'</span><span class="p">)</span>
|
| 69 |
+
<span class="n">run</span><span class="o">.</span><span class="n">feature_gen</span><span class="p">()</span>
|
| 70 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s1">'New features: (index-0:22 original samples, else is GAN generated)'</span><span class="p">,</span><span class="n">run</span><span class="o">.</span><span class="n">df</span><span class="o">.</span><span class="n">iloc</span><span class="p">[</span><span class="mi">1</span><span class="p">:,</span><span class="mi">9</span><span class="p">:]</span><span class="o">.</span><span class="n">astype</span><span class="p">(</span><span class="nb">float</span><span class="p">))</span>
|
| 71 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s1">'Most of real dataset is from *doi:0.2514/1.B37424*, hence the results mostly agree with it in specific'</span><span class="p">)</span>
|
| 72 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.feature_importance(run.df.iloc[1:,1:7].astype(float),run.df.iloc[1:,7]) # Clear and easy example'</span><span class="p">)</span>
|
| 73 |
+
|
| 74 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">run</span><span class="o">.</span><span class="n">feature_importance</span><span class="p">(</span><span class="n">run</span><span class="o">.</span><span class="n">df</span><span class="o">.</span><span class="n">iloc</span><span class="p">[</span><span class="mi">1</span><span class="p">:,</span><span class="mi">1</span><span class="p">:</span><span class="mi">6</span><span class="p">]</span><span class="o">.</span><span class="n">astype</span><span class="p">(</span><span class="nb">float</span><span class="p">),</span><span class="n">run</span><span class="o">.</span><span class="n">df</span><span class="o">.</span><span class="n">iloc</span><span class="p">[</span><span class="mi">1</span><span class="p">:,</span><span class="mi">6</span><span class="p">]))</span>
|
| 75 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span><span class="s1">' As we can see only $h$ and $d$ passed for $m_a$ model, not only that linear dependacy was proven experimantally, but now we got this from data driven source'</span><span class="p">)</span>
|
| 76 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.compile(idx=(1,3,7))'</span><span class="p">)</span>
|
| 77 |
+
<span class="n">run</span><span class="o">.</span><span class="n">compile</span><span class="p">(</span><span class="n">idx</span><span class="o">=</span><span class="p">(</span><span class="mi">1</span><span class="p">,</span><span class="mi">3</span><span class="p">,</span><span class="mi">7</span><span class="p">))</span>
|
| 78 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.train(epochs=10)'</span><span class="p">)</span>
|
| 79 |
+
<span class="n">run</span><span class="o">.</span><span class="n">train</span><span class="p">(</span><span class="n">epochs</span><span class="o">=</span><span class="mi">10</span><span class="p">)</span>
|
| 80 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.plot3d()'</span><span class="p">)</span>
|
| 81 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">run</span><span class="o">.</span><span class="n">plot3d</span><span class="p">())</span>
|
| 82 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.performance()'</span><span class="p">)</span>
|
| 83 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">run</span><span class="o">.</span><span class="n">performance</span><span class="p">())</span>
|
| 84 |
+
|
| 85 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s1">'Try it out yourself! Select a column from 1 to 10'</span><span class="p">)</span>
|
| 86 |
+
<span class="n">number</span> <span class="o">=</span> <span class="n">st</span><span class="o">.</span><span class="n">number_input</span><span class="p">(</span><span class="s1">'Here'</span><span class="p">,</span><span class="n">min_value</span><span class="o">=</span><span class="mi">1</span><span class="p">,</span> <span class="n">max_value</span><span class="o">=</span><span class="mi">10</span><span class="p">,</span> <span class="n">step</span><span class="o">=</span><span class="mi">1</span><span class="p">)</span>
|
| 87 |
+
|
| 88 |
+
<span class="k">if</span> <span class="n">number</span><span class="p">:</span>
|
| 89 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="sa">f</span><span class="s1">'run.compile(idx=(1,3,</span><span class="si">{</span><span class="n">number</span><span class="si">}</span><span class="s1">))'</span><span class="p">)</span>
|
| 90 |
+
<span class="n">run</span><span class="o">.</span><span class="n">compile</span><span class="p">(</span><span class="n">idx</span><span class="o">=</span><span class="p">(</span><span class="mi">1</span><span class="p">,</span><span class="mi">3</span><span class="p">,</span><span class="n">number</span><span class="p">))</span>
|
| 91 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.train(epochs=10)'</span><span class="p">)</span>
|
| 92 |
+
<span class="n">run</span><span class="o">.</span><span class="n">train</span><span class="p">(</span><span class="n">epochs</span><span class="o">=</span><span class="mi">10</span><span class="p">)</span>
|
| 93 |
+
<span class="n">st</span><span class="o">.</span><span class="n">code</span><span class="p">(</span><span class="s1">'run.plot3d()'</span><span class="p">)</span>
|
| 94 |
+
<span class="n">st</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">run</span><span class="o">.</span><span class="n">plot3d</span><span class="p">())</span>
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
<span class="n">st</span><span class="o">.</span><span class="n">markdown</span><span class="p">(</span><span class="s1">'In this intro we covered simplest user flow while using HETFit package, resulted data can be used to leverage PINN and analytical models of Hall effect thrusters'</span>
|
| 99 |
+
<span class="s1">'</span><span class="se">\n</span><span class="s1"> #### :orange[To cite please contact author on https://github.com/advpropsys]'</span><span class="p">)</span>
|
| 100 |
+
|
| 101 |
+
</pre></div>
|
| 102 |
+
</div>
|
| 103 |
+
</div>
|
| 104 |
+
<div class='clearall'></div>
|
| 105 |
+
</div>
|
| 106 |
+
</body>
|
fig1.png
ADDED

|
gan.png
ADDED

|
gen.png
ADDED

|
geom.png
ADDED

|
graph.jpg
ADDED

|
intro.md
ADDED
|
@@ -0,0 +1,453 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# :orange[Abstract:]
|
| 2 |
+
Hall effect thrusters are one of the most versatile and
|
| 3 |
+
popular electric propulsion systems for space use. Industry trends
|
| 4 |
+
towards interplanetary missions arise advances in design development
|
| 5 |
+
of such propulsion systems. It is understood that correct sizing of
|
| 6 |
+
discharge channel in Hall effect thruster impact performance greatly.
|
| 7 |
+
Since the complete physics model of such propulsion system is not yet
|
| 8 |
+
optimized for fast computations and design iterations, most thrusters
|
| 9 |
+
are being designed using so-called scaling laws. But this work focuses
|
| 10 |
+
on rather novel approach, which is outlined less frequently than
|
| 11 |
+
ordinary scaling design approach in literature. Using deep machine
|
| 12 |
+
learning it is possible to create predictive performance model, which
|
| 13 |
+
can be used to effortlessly get design of required hall thruster with
|
| 14 |
+
required characteristics using way less computing power than design
|
| 15 |
+
from scratch and way more flexible than usual scaling approach.
|
| 16 |
+
:orange[author:] Korolev K.V [^1]
|
| 17 |
+
title: Hall effect thruster design via deep neural network for additive
|
| 18 |
+
manufacturing
|
| 19 |
+
|
| 20 |
+
# Nomenclature
|
| 21 |
+
|
| 22 |
+
<div class="longtable*" markdown="1">
|
| 23 |
+
|
| 24 |
+
$U_d$ = discharge voltage
|
| 25 |
+
$P$ = discharge power
|
| 26 |
+
$T$ = thrust
|
| 27 |
+
$\dot{m}_a$ = mass flow rate
|
| 28 |
+
$I_{sp}$ = specific impulse
|
| 29 |
+
$\eta_m$ = mass utilization efficiency
|
| 30 |
+
$\eta_a$ = anode efficiency
|
| 31 |
+
$j$ = $P/v$ \[power density\]
|
| 32 |
+
$v$ = discharge channel volume
|
| 33 |
+
$h, d, L$ = generic geometry parameters
|
| 34 |
+
$C_*$ = set of scaling coefficients
|
| 35 |
+
$g$ = free-fall acceleration
|
| 36 |
+
$M$ = ion mass
|
| 37 |
+
|
| 38 |
+
</div>
|
| 39 |
+
|
| 40 |
+
# Introduction
|
| 41 |
+
|
| 42 |
+
<span class="lettrine">T</span><span class="smallcaps">he</span>
|
| 43 |
+
application of deep learning is extremely diverse, but in this study it
|
| 44 |
+
focuses on case of hall effect thruster design. Hall effect thruster
|
| 45 |
+
(HET) is rather simple DC plasma acceleration device, due to complex and
|
| 46 |
+
non linear process physics we don’t have any full analytical performance
|
| 47 |
+
models yet. Though there are a lot of ways these systems are designed in
|
| 48 |
+
industry with great efficiencies, but in cost of multi-million research
|
| 49 |
+
budgets and time. This problem might be solved using neural network
|
| 50 |
+
design approach and few hardware iteration tweaks(Plyashkov et al.
|
| 51 |
+
2022-10-25).
|
| 52 |
+
|
| 53 |
+
Scaled thrusters tend to have good performance but this approach isn’t
|
| 54 |
+
that flexible for numerous reasons: first and foremost, due to large
|
| 55 |
+
deviations in all of the initial experimental values accuracy can be not
|
| 56 |
+
that good, secondly, it is hardly possible to design thruster with
|
| 57 |
+
different power density or $I_{sp}$ efficiently.
|
| 58 |
+
|
| 59 |
+
On the other hand, the neural network design approach has accuracy
|
| 60 |
+
advantage only on domain of the dataset(Plyashkov et al. 2022-10-25),
|
| 61 |
+
this limitations is easily compensated by ability to create relations
|
| 62 |
+
between multiple discharge and geometry parameters at once. Hence this
|
| 63 |
+
novel approach and scaling relations together could be an ultimate
|
| 64 |
+
endgame design tool for HET.
|
| 65 |
+
|
| 66 |
+
Note that neither of these models do not include cathode efficiencies
|
| 67 |
+
and performances. So as the neutral gas thrust components. Most
|
| 68 |
+
correlations in previous literature were made using assumption or
|
| 69 |
+
physics laws(Shagayda and Gorshkov 2013-03), in this paper the new
|
| 70 |
+
method based on feature generation, GAN dataset augmentation and ML
|
| 71 |
+
feature selection is suggested.
|
| 72 |
+
|
| 73 |
+
## Dataset enlargement using GAN
|
| 74 |
+
|
| 75 |
+
As we already have discussed, the data which is available is not enough
|
| 76 |
+
for training NN or most ML algorithms, so I suggest using Generative
|
| 77 |
+
Adversarial Network to generate more similar points. Generative model
|
| 78 |
+
trains two different models - generator and discriminator. Generator
|
| 79 |
+
learns how to generate new points which are classified by discriminator
|
| 80 |
+
as similar to real dataset. Of course it is very understandable that
|
| 81 |
+
model needs to be precise enough not to overfit on data or create new
|
| 82 |
+
unknown correlations. Model was checked via Mean Absolute Percentage
|
| 83 |
+
Error (MAPE) and physical boundary conditions. After assembling most
|
| 84 |
+
promising architecture, the model was able to generate fake points with
|
| 85 |
+
MAPE of $~4.7\%$. We need to measure MAPE to be sure point lie on same
|
| 86 |
+
domain as original dataset, as in this work we are interested in
|
| 87 |
+
sub-kilowatt thrusters. After model generated new points they were check
|
| 88 |
+
to fit in physical boundaries of scaled values (for example thrust
|
| 89 |
+
couldn’t be more than 2, efficiency more than 1.4 and so on, data was
|
| 90 |
+
scaled on original dataset to retain quality), only 0.02% of points were
|
| 91 |
+
found to be outliers. The GAN architecture and dataset sample is
|
| 92 |
+
provided as follows.
|
| 93 |
+
|
| 94 |
+
<!-- 
|
| 95 |
+
 -->
|
| 96 |
+
|
| 97 |
+
# General Relations
|
| 98 |
+
|
| 99 |
+
As we will use dataset of only low power hall thrusters, we can just
|
| 100 |
+
ignore derivation of any non-linear equations and relations and use
|
| 101 |
+
traditional approach here. Let’s define some parameters of anode:
|
| 102 |
+
$$\alpha = \frac{\dot{m}\beta}{{\dot{m}_a}},$$
|
| 103 |
+
Where $\alpha$ is anode
|
| 104 |
+
parameter of $\beta$ thruster parameter. This is selected because this
|
| 105 |
+
way cathode and other losses wont be included in the model. One of key
|
| 106 |
+
differences in this approach is fitting only best and most appropriate
|
| 107 |
+
data, thus we will eliminate some variance in scaling laws. Though due
|
| 108 |
+
to machine learning methods, we would need a lot of information which is
|
| 109 |
+
simply not available in those volumes. So some simplifications and
|
| 110 |
+
assumptions could be made. Firstly, as it was already said, we don’t
|
| 111 |
+
include neutralizer efficiency in the model. Secondly, the model would
|
| 112 |
+
be correct on very specific domain, defined by dataset, many parameters
|
| 113 |
+
like anode power and $I_{sp}$ still are using semi-empirical modelling
|
| 114 |
+
approach. The results we are looking for are outputs of machine learning
|
| 115 |
+
algorithm: specific impulse, thrust, efficiency, optimal mass flow rate,
|
| 116 |
+
power density. Function of input is solely dependant on power and
|
| 117 |
+
voltage range. For the matter of topic let’s introduce semi-empirical
|
| 118 |
+
equations which are used for scaling current thrusters.
|
| 119 |
+
|
| 120 |
+
<div class="longtable*" markdown="2">
|
| 121 |
+
|
| 122 |
+
$$h=C_hd$$
|
| 123 |
+
|
| 124 |
+
$$\dot{m_a} = C_m hd$$
|
| 125 |
+
|
| 126 |
+
$$P_d=C_pU_dd^2$$
|
| 127 |
+
|
| 128 |
+
$$T=C_t\dot{m_a}\sqrt{U_d}$$
|
| 129 |
+
|
| 130 |
+
$$I_{spa}=\frac{T}{\dot{m_a} g}$$
|
| 131 |
+
|
| 132 |
+
$$\eta_a=\frac{T}{2\dot{m_a}P_d}$$
|
| 133 |
+
|
| 134 |
+
</div>
|
| 135 |
+
|
| 136 |
+
Where $C_x$ is scaling coefficient obtained from analytical modelling,
|
| 137 |
+
which makes equations linear. Generally it has 95% prediction band but
|
| 138 |
+
as was said earlier this linearity is what gives problems to current
|
| 139 |
+
thrusters designs (high mass, same power density, average performance).
|
| 140 |
+
The original dataset is
|
| 141 |
+
|
| 142 |
+
| | | | | | | | | |
|
| 143 |
+
|:---------|:---------|:-------|:------|:------|:------|:-------------|:-----|:----------|
|
| 144 |
+
| Thruster | Power, W | U_d, V | d, mm | h, mm | L, mm | m_a,.g/s, | T, N | I\_spa, s |
|
| 145 |
+
| SPT-20 | 52.4 | 180 | 15.0 | 5.0 | 32.0 | 0.47 | 3.9 | 839 |
|
| 146 |
+
| SPT-25 | 134 | 180 | 20.0 | 5.0 | 10 | 0.59 | 5.5 | 948 |
|
| 147 |
+
| Music-si | 140 | 288 | 18 | 2 | 6.5 | 0.44 | 4.2 | 850 |
|
| 148 |
+
| HET-100 | 174 | 300 | 23.5 | 5.5 | 14.5 | 0.50 | 6.8 | 1386 |
|
| 149 |
+
| KHT-40 | 187 | 325 | 31.0 | 9.0 | 25.5 | 0.69 | 10.3 | 1519 |
|
| 150 |
+
| KHT-50 | 193 | 250 | 42.0 | 8.0 | 25.0 | 0.88 | 11.6 | 1339 |
|
| 151 |
+
| HEPS-200 | 195 | 250 | 42.5 | 8.5 | 25.0 | 0.88 | 11.2 | 1300 |
|
| 152 |
+
| BHT-200 | 200 | 250 | 21.0 | 5.6 | 11.2 | 0.94 | 12.8 | 1390 |
|
| 153 |
+
| KM-32 | 215 | 250 | 32.0 | 7.0 | 16.0 | 1.00 | 12.2 | 1244 |
|
| 154 |
+
| ... | | | | | | | | |
|
| 155 |
+
| HEPS-500 | 482 | 300 | 49.5 | 15.5 | 25.0 | 1.67 | 25.9 | 1587 |
|
| 156 |
+
| UAH-78AM | 520 | 260 | 78.0 | 20 | 40 | 2 | 30 | 1450 |
|
| 157 |
+
| BHT-600 | 615 | 300 | 56.0 | 16.0 | 32 | 2.60 | 39.1 | 1530 |
|
| 158 |
+
| SPT-70 | 660 | 300 | 56.0 | 14.0 | 25.0 | 2.56 | 40.0 | 1593 |
|
| 159 |
+
| MaSMi60 | 700 | 250 | 60 | 9.42 | 19 | 2.56 | 30 | 1300 |
|
| 160 |
+
| MaSMiDm | 1000 | 500 | 67 | 10.5 | 21 | 3 | 53 | 1940 |
|
| 161 |
+
| SPT-100 | 1350 | 300 | 85.0 | 15.0 | 25.0 | 5.14 | 81.6 | 1540 |
|
| 162 |
+
|
| 163 |
+
Hosting only 24 entries in total. The references are as follows(Beal et
|
| 164 |
+
al. 2004-11)(Belikov et al. 2001-07-08)(Kronhaus et al. 2013-07)(Misuri
|
| 165 |
+
and Andrenucci 2008-07-21)(Lee et al. 2019-11)
|
| 166 |
+
|
| 167 |
+
In the next section the used neural networks architectures will be
|
| 168 |
+
discussed.
|
| 169 |
+
|
| 170 |
+
# Data driven HET designs
|
| 171 |
+
|
| 172 |
+
Neural networks are a type of machine learning algorithm that is often
|
| 173 |
+
used in the field of artificial intelligence. They are mathematical
|
| 174 |
+
models that can be trained to recognize patterns within large datasets.
|
| 175 |
+
The architecture of GAN’s generator was already shown. In this section
|
| 176 |
+
we will focus on fully connected networks, which are most popular for
|
| 177 |
+
type for these tasks. HETFit code leverages dynamic architecture
|
| 178 |
+
generation of these FcNN’s which is done via meta learning algorithm
|
| 179 |
+
Tree-structured Parzen Estimator for every data input user selects. This
|
| 180 |
+
code uses state-of-art implementation made by OPTUNA. The dynamically
|
| 181 |
+
suggested architecture has 2 to 6 layers from 4 to 128 nodes on each
|
| 182 |
+
with SELU, Tanh or ReLU activations and most optimal optimizer. The code
|
| 183 |
+
user interface is as follows: 1. Specify working environment 2. Load or
|
| 184 |
+
generate data 3. Tune the architecture 4. Train and get robust scaling
|
| 185 |
+
models
|
| 186 |
+
|
| 187 |
+
## FNN
|
| 188 |
+
|
| 189 |
+
All of Fully connected neural networks are implemented in PyTorch as it
|
| 190 |
+
the most powerful ML/AI library for experiments. When the network
|
| 191 |
+
architecture is generated, all of networks have similar training loops
|
| 192 |
+
as they use gradient descend algorithm : Loss function:
|
| 193 |
+
$$L(w, b) \equiv \frac{1}{2 n} \sum_x\|y(x)-a\|^2$$ This one is mean
|
| 194 |
+
square error (MSE) error function most commonly used in FNNs. Next we
|
| 195 |
+
iterate while updating weights for a number of specified epochs this
|
| 196 |
+
way. Loop for number of epochs:
|
| 197 |
+
|
| 198 |
+
\- Get predictions: $\hat{y}$
|
| 199 |
+
|
| 200 |
+
\- Compute loss: $\mathscr{L}(w, b)$
|
| 201 |
+
|
| 202 |
+
\- Make backward pass
|
| 203 |
+
|
| 204 |
+
\- Update optimizer
|
| 205 |
+
|
| 206 |
+
It can be mentioned that dataset of electric propulsion is extremely
|
| 207 |
+
complex due to large deviations in data. Thanks to adavnces in data
|
| 208 |
+
science and ML it is possible to work with it.
|
| 209 |
+
|
| 210 |
+
This way we assembled dataset on our ROI domain of $P$\<1000 $W$ input
|
| 211 |
+
power and 200-500 $V$ range. Sadly one of limitations of such model is
|
| 212 |
+
disability to go beyond actual database limit while not sacrificing
|
| 213 |
+
performance and accuracy.
|
| 214 |
+
|
| 215 |
+
## Physics Informed Neural Networks
|
| 216 |
+
|
| 217 |
+
For working with unscaled data PINN’s were introduced, they are using
|
| 218 |
+
equations 2-7 to generate $C_x$ coefficients. Yes, it was said earlier
|
| 219 |
+
that this method lacks ability to generate better performing HETs, but
|
| 220 |
+
as we have generated larger dataset on same domain as Lee et al.
|
| 221 |
+
(2019-11) it is important to control that our dataset is still the same
|
| 222 |
+
quality as original. Using above mentioned PINN’s it was possible to fit
|
| 223 |
+
coefficients and they showed only slight divergence in values of few %
|
| 224 |
+
which is acceptable.
|
| 225 |
+
|
| 226 |
+
## ML approach notes
|
| 227 |
+
|
| 228 |
+
We already have discussed how HETFit code works and results it can
|
| 229 |
+
generate, the overiew is going to be given in next section. But here i
|
| 230 |
+
want to warn that this work is highly experimental and you should always
|
| 231 |
+
take ML approaches with a grain of salt, as some plasma discharge
|
| 232 |
+
physics in HET is yet to be understood, data driven way may have some
|
| 233 |
+
errors in predictions on specific bands. Few notes on design tool I have
|
| 234 |
+
developed in this work: it is meant to be used by people with little to
|
| 235 |
+
no experience in ML field but those who wants to quickly analyze their
|
| 236 |
+
designs or create baseline one for simulations. One can even use this
|
| 237 |
+
tool for general tabular data as it has mostly no limits whatsoever to
|
| 238 |
+
input data.
|
| 239 |
+
|
| 240 |
+
## Two input variables prediction
|
| 241 |
+
|
| 242 |
+
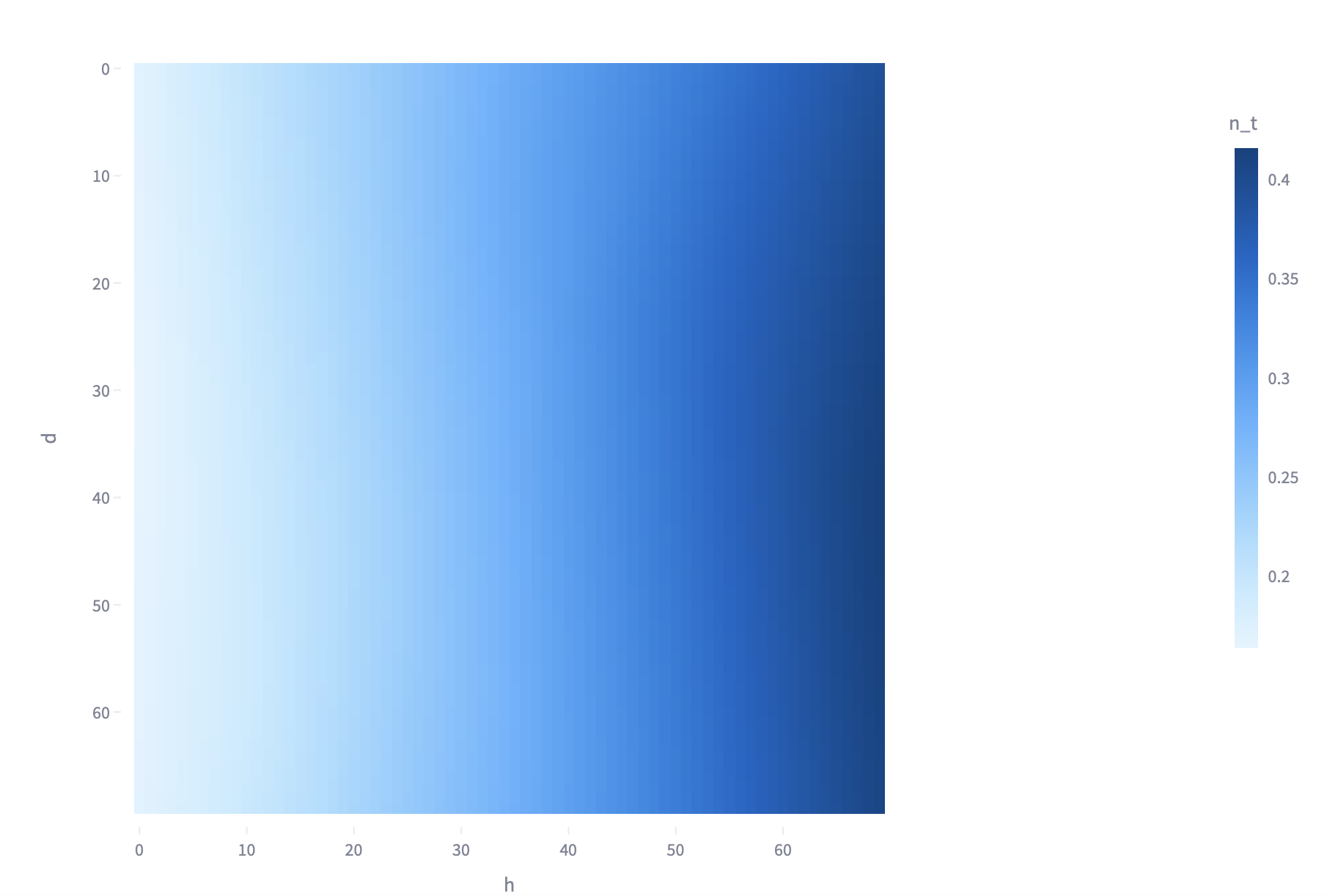
One of main characteristics for any type of thruster is efficiency, in
|
| 243 |
+
this work I researched dependency of multiple input values to $\eta_t$.
|
| 244 |
+
Results are as follows in form of predicted matrix visualisations.
|
| 245 |
+
Figure 3 takes into account all previous ones in the same time, once
|
| 246 |
+
again it would be way harder to do without ML.
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
# Results discussion
|
| 251 |
+
|
| 252 |
+
Let’s compare predictions of semi empirical approach(Lee et al.
|
| 253 |
+
2019-11), approach in paper(Plyashkov et al. 2022-10-25), and finally
|
| 254 |
+
ours. Worth to mention that current approach is easiest to redesign from
|
| 255 |
+
scratch.
|
| 256 |
+
|
| 257 |
+
## NN architecture generation algorithm
|
| 258 |
+
|
| 259 |
+
As with 50 iterations, previously discussed meta learning model is able
|
| 260 |
+
to create architecture with score of 0.9+ in matter of seconds. HETFit
|
| 261 |
+
allows logging into neptune.ai environment for full control over
|
| 262 |
+
simulations. Example trail run looks like that.
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
## Power density and magnetic flux dependence
|
| 267 |
+
|
| 268 |
+
Neither of the models currently support taking magnetic flux in account
|
| 269 |
+
besides general physics relations, but we are planning on updating the
|
| 270 |
+
model in next follow up paper. For now $\vec{B}$ relation to power
|
| 271 |
+
remains unresolved to ML approach but the magnetic field distribution on
|
| 272 |
+
z axis is computable and looks like that for magnetically shielded
|
| 273 |
+
thrusters:
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
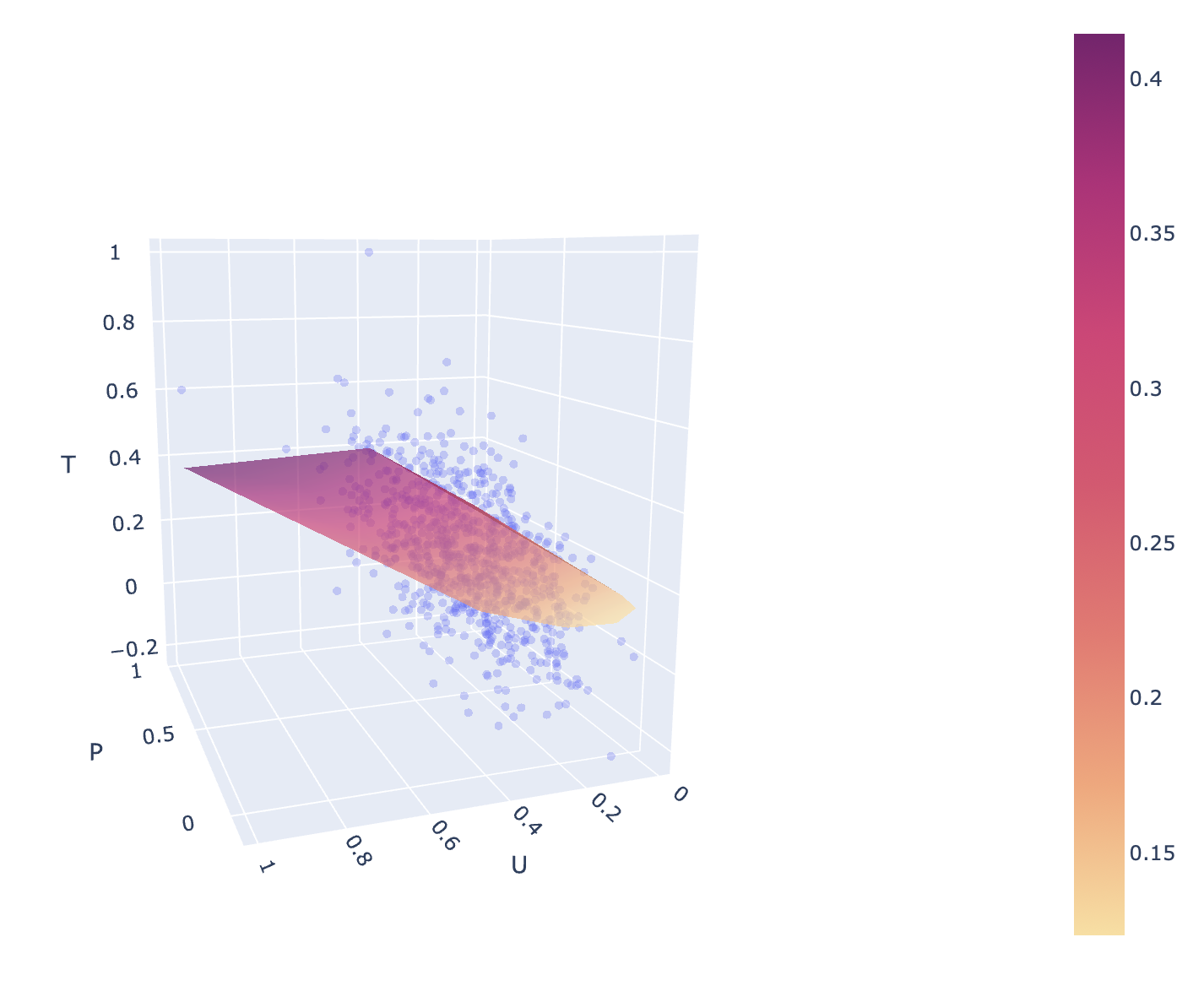
## Dependency of T on d,P
|
| 278 |
+
|
| 279 |
+
Following graph is describing Thrust as function of channel diameter and
|
| 280 |
+
width, where hue map is thrust. It is well known dependency and it has
|
| 281 |
+
few around 95% prediction band (Lee et al. 2019-11)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
## Dependency of T on P,U
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
## Dependency of T on $m_a$,P
|
| 290 |
+
|
| 291 |
+
Compared to(Shagayda and Gorshkov 2013-03) The model accounts for more
|
| 292 |
+
parameters than linear relation. So such method proves to be more
|
| 293 |
+
precise on specified domain than semi empirical linear relations.
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
## Dependency of $I_{sp}$ on d,h
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
We generated many models so far, but using ML we can make single model
|
| 302 |
+
for all of the parameters at the same time, so these graphs tend to be
|
| 303 |
+
3d projection of such model inference.
|
| 304 |
+
|
| 305 |
+
## Use of pretrained model in additive manufacturing of hall effect thruster channels
|
| 306 |
+
|
| 307 |
+
The above mentioned model was used to predict geometry of channel, next
|
| 308 |
+
the simulation was conducted on this channel. Second one for comparison
|
| 309 |
+
was calculated via usual scaling laws. The initial conditions for both
|
| 310 |
+
are:
|
| 311 |
+
|
| 312 |
+
| Initial condition | Value |
|
| 313 |
+
|:------------------|:------------------|
|
| 314 |
+
| $n_{e,0}$ | 1e13 \[m\^-3\] |
|
| 315 |
+
| $\epsilon_0$ | 4 \[V\] |
|
| 316 |
+
| V | 300 \[V\] |
|
| 317 |
+
| T | 293.15 \[K\] |
|
| 318 |
+
| P\_abs | 0.5 \[torr\] |
|
| 319 |
+
| $\mu_e N_n$ | 1e25 \[1/(Vm s)\] |
|
| 320 |
+
| dt | 1e-8 \[s\] |
|
| 321 |
+
| Body | Ar |
|
| 322 |
+
|
| 323 |
+
Outcomes are so that ML geometry results in higher density generation of
|
| 324 |
+
ions which leads to more efficient thrust generation. HETFit code
|
| 325 |
+
suggests HET parameters by lower estimate to compensate for not included
|
| 326 |
+
variables in model of HET. This is experimentally proven to be efficient
|
| 327 |
+
estimate since SEM predictions of thrust are always higher than real
|
| 328 |
+
performance. Lee et al. (2019-11)
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
## Code description
|
| 333 |
+
|
| 334 |
+
Main concepts: - Each observational/design session is called an
|
| 335 |
+
environment, for now it can be either RCI or SCI (Real or scaled
|
| 336 |
+
interface)
|
| 337 |
+
|
| 338 |
+
\- Most of the run parameters are specified on this object
|
| 339 |
+
initialization, including generation of new samples via GAN
|
| 340 |
+
|
| 341 |
+
\- Built-in feature generation (log10 Power, efficiency, $\vec{B}$,
|
| 342 |
+
etc.)
|
| 343 |
+
|
| 344 |
+
\- Top feature selection for each case. (Boruta algorithm)
|
| 345 |
+
|
| 346 |
+
\- Compilation of environment with model of choice, can be any torch
|
| 347 |
+
model or sklearn one
|
| 348 |
+
|
| 349 |
+
\- Training
|
| 350 |
+
|
| 351 |
+
\- Plot, inference, save, export to jit/onnx, measure performance
|
| 352 |
+
|
| 353 |
+
## COMSOL HET simulations
|
| 354 |
+
|
| 355 |
+
The simulations were conducted in COMSOL in plasma physics interface
|
| 356 |
+
which gives the ability to accurately compute Electron densities,
|
| 357 |
+
temperatures, energy distribution functions from initial conditions and
|
| 358 |
+
geometry. Here is comparison of both channels.
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
# Conclusion
|
| 363 |
+
|
| 364 |
+
In conclusion the another model of scaling laws was made and presented.
|
| 365 |
+
HETFit code is open source and free to be used by anyone. Additively
|
| 366 |
+
manufactured channel was printed to prove it’s manufactureability.
|
| 367 |
+
Hopefully this work will help developing more modern scaling relations
|
| 368 |
+
as current ones are far from perfect.
|
| 369 |
+
|
| 370 |
+
Method in this paper and firstly used in Plyashkov et al. (2022-10-25)
|
| 371 |
+
has advantages over SEM one in: ability to preidct performance more
|
| 372 |
+
precisely on given domain, account for experimental data. I believe with
|
| 373 |
+
more input data the ML method of deisgning thrusters would be more
|
| 374 |
+
widely used.
|
| 375 |
+
|
| 376 |
+
The code in this work could be used with other tabular experimental data
|
| 377 |
+
since most of cases and tasks tend to be the same: feature selection and
|
| 378 |
+
model optimization.
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
<div id="refs" class="references csl-bib-body hanging-indent"
|
| 382 |
+
markdown="1">
|
| 383 |
+
|
| 384 |
+
<div id="ref-beal_plasma_2004" class="csl-entry" markdown="1">
|
| 385 |
+
|
| 386 |
+
Beal, Brian E., Alec D. Gallimore, James M. Haas, and William A. Hargus.
|
| 387 |
+
2004-11. “Plasma Properties in the Plume of a Hall Thruster Cluster.”
|
| 388 |
+
*Journal of Propulsion and Power* 20 (6): 985–91.
|
| 389 |
+
<https://doi.org/10.2514/1.3765>.
|
| 390 |
+
|
| 391 |
+
</div>
|
| 392 |
+
|
| 393 |
+
<div id="ref-belikov_high-performance_2001" class="csl-entry"
|
| 394 |
+
markdown="1">
|
| 395 |
+
|
| 396 |
+
Belikov, M., O. Gorshkov, V. Muravlev, R. Rizakhanov, A. Shagayda, and
|
| 397 |
+
A. Snnirev. 2001-07-08. “High-Performance Low Power Hall Thruster.” In
|
| 398 |
+
*37th Joint Propulsion Conference and Exhibit*. Salt Lake
|
| 399 |
+
City,UT,U.S.A.: American Institute of Aeronautics; Astronautics.
|
| 400 |
+
<https://doi.org/10.2514/6.2001-3780>.
|
| 401 |
+
|
| 402 |
+
</div>
|
| 403 |
+
|
| 404 |
+
<div id="ref-kronhaus_discharge_2013" class="csl-entry" markdown="1">
|
| 405 |
+
|
| 406 |
+
Kronhaus, Igal, Alexander Kapulkin, Vladimir Balabanov, Maksim
|
| 407 |
+
Rubanovich, Moshe Guelman, and Benveniste Natan. 2013-07. “Discharge
|
| 408 |
+
Characterization of the Coaxial Magnetoisolated Longitudinal Anode Hall
|
| 409 |
+
Thruster.” *Journal of Propulsion and Power* 29 (4): 938–49.
|
| 410 |
+
<https://doi.org/10.2514/1.B34754>.
|
| 411 |
+
|
| 412 |
+
</div>
|
| 413 |
+
|
| 414 |
+
<div id="ref-lee_scaling_2019" class="csl-entry" markdown="1">
|
| 415 |
+
|
| 416 |
+
Lee, Eunkwang, Younho Kim, Hodong Lee, Holak Kim, Guentae Doh, Dongho
|
| 417 |
+
Lee, and Wonho Choe. 2019-11. “Scaling Approach for Sub-Kilowatt
|
| 418 |
+
Hall-Effect Thrusters.” *Journal of Propulsion and Power* 35 (6):
|
| 419 |
+
1073–79. <https://doi.org/10.2514/1.B37424>.
|
| 420 |
+
|
| 421 |
+
</div>
|
| 422 |
+
|
| 423 |
+
<div id="ref-misuri_het_2008" class="csl-entry" markdown="1">
|
| 424 |
+
|
| 425 |
+
Misuri, Tommaso, and Mariano Andrenucci. 2008-07-21. “HET Scaling
|
| 426 |
+
Methodology: Improvement and Assessment.” In *44th AIAA/ASME/SAE/ASEE
|
| 427 |
+
Joint Propulsion Conference &Amp; Exhibit*. Hartford, CT: American
|
| 428 |
+
Institute of Aeronautics; Astronautics.
|
| 429 |
+
<https://doi.org/10.2514/6.2008-4806>.
|
| 430 |
+
|
| 431 |
+
</div>
|
| 432 |
+
|
| 433 |
+
<div id="ref-plyashkov_scaling_2022" class="csl-entry" markdown="1">
|
| 434 |
+
|
| 435 |
+
Plyashkov, Yegor V., Andrey A. Shagayda, Dmitrii A. Kravchenko, Fedor D.
|
| 436 |
+
Ratnikov, and Alexander S. Lovtsov. 2022-10-25. “On Scaling of
|
| 437 |
+
Hall-Effect Thrusters Using Neural Nets,” 2022-10-25.
|
| 438 |
+
<http://arxiv.org/abs/2206.04440>.
|
| 439 |
+
|
| 440 |
+
</div>
|
| 441 |
+
|
| 442 |
+
<div id="ref-shagayda_hall-thruster_2013" class="csl-entry"
|
| 443 |
+
markdown="1">
|
| 444 |
+
|
| 445 |
+
Shagayda, Andrey A., and Oleg A. Gorshkov. 2013-03. “Hall-Thruster
|
| 446 |
+
Scaling Laws.” *Journal of Propulsion and Power* 29 (2): 466–74.
|
| 447 |
+
<https://doi.org/10.2514/1.B34650>.
|
| 448 |
+
|
| 449 |
+
</div>
|
| 450 |
+
|
| 451 |
+
</div>
|
| 452 |
+
|
| 453 |
+
[^1]: Founder, Pure EP
|
invariant.png
ADDED

|
maT.png
ADDED

|
main.md
ADDED
|
@@ -0,0 +1,1060 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Table of Contents
|
| 2 |
+
|
| 3 |
+
- [Table of Contents](#table-of-contents)
|
| 4 |
+
- [main](#main)
|
| 5 |
+
- [PINN](#pinn)
|
| 6 |
+
- [PINN.pinns](#pinnpinns)
|
| 7 |
+
- [PINNd\_p Objects](#pinnd_p-objects)
|
| 8 |
+
- [forward](#forward)
|
| 9 |
+
- [PINNhd\_ma Objects](#pinnhd_ma-objects)
|
| 10 |
+
- [PINNT\_ma Objects](#pinnt_ma-objects)
|
| 11 |
+
- [utils](#utils)
|
| 12 |
+
- [utils.test](#utilstest)
|
| 13 |
+
- [utils.dataset\_loader](#utilsdataset_loader)
|
| 14 |
+
- [get\_dataset](#get_dataset)
|
| 15 |
+
- [utils.ndgan](#utilsndgan)
|
| 16 |
+
- [DCGAN Objects](#dcgan-objects)
|
| 17 |
+
- [\_\_init\_\_](#__init__)
|
| 18 |
+
- [define\_discriminator](#define_discriminator)
|
| 19 |
+
- [define\_generator](#define_generator)
|
| 20 |
+
- [build\_models](#build_models)
|
| 21 |
+
- [generate\_latent\_points](#generate_latent_points)
|
| 22 |
+
- [generate\_fake\_samples](#generate_fake_samples)
|
| 23 |
+
- [define\_gan](#define_gan)
|
| 24 |
+
- [summarize\_performance](#summarize_performance)
|
| 25 |
+
- [train\_gan](#train_gan)
|
| 26 |
+
- [start\_training](#start_training)
|
| 27 |
+
- [predict](#predict)
|
| 28 |
+
- [utils.data\_augmentation](#utilsdata_augmentation)
|
| 29 |
+
- [dataset Objects](#dataset-objects)
|
| 30 |
+
- [\_\_init\_\_](#__init__-1)
|
| 31 |
+
- [generate](#generate)
|
| 32 |
+
- [:orange\[nets\]](#orangenets)
|
| 33 |
+
- [nets.envs](#netsenvs)
|
| 34 |
+
- [SCI Objects](#sci-objects)
|
| 35 |
+
- [\_\_init\_\_](#__init__-2)
|
| 36 |
+
- [feature\_gen](#feature_gen)
|
| 37 |
+
- [feature\_importance](#feature_importance)
|
| 38 |
+
- [data\_flow](#data_flow)
|
| 39 |
+
- [init\_seed](#init_seed)
|
| 40 |
+
- [train\_epoch](#train_epoch)
|
| 41 |
+
- [compile](#compile)
|
| 42 |
+
- [train](#train)
|
| 43 |
+
- [save](#save)
|
| 44 |
+
- [onnx\_export](#onnx_export)
|
| 45 |
+
- [jit\_export](#jit_export)
|
| 46 |
+
- [inference](#inference)
|
| 47 |
+
- [plot](#plot)
|
| 48 |
+
- [plot3d](#plot3d)
|
| 49 |
+
- [performance](#performance)
|
| 50 |
+
- [performance\_super](#performance_super)
|
| 51 |
+
- [RCI Objects](#rci-objects)
|
| 52 |
+
- [data\_flow](#data_flow-1)
|
| 53 |
+
- [compile](#compile-1)
|
| 54 |
+
- [plot](#plot-1)
|
| 55 |
+
- [performance](#performance-1)
|
| 56 |
+
- [nets.dense](#netsdense)
|
| 57 |
+
- [Net Objects](#net-objects)
|
| 58 |
+
- [\_\_init\_\_](#__init__-3)
|
| 59 |
+
- [nets.design](#netsdesign)
|
| 60 |
+
- [B\_field\_norm](#b_field_norm)
|
| 61 |
+
- [PUdesign](#pudesign)
|
| 62 |
+
- [nets.deep\_dense](#netsdeep_dense)
|
| 63 |
+
- [dmodel Objects](#dmodel-objects)
|
| 64 |
+
- [\_\_init\_\_](#__init__-4)
|
| 65 |
+
- [nets.opti](#netsopti)
|
| 66 |
+
- [nets.opti.blackbox](#netsoptiblackbox)
|
| 67 |
+
- [Hyper Objects](#hyper-objects)
|
| 68 |
+
- [\_\_init\_\_](#__init__-5)
|
| 69 |
+
- [define\_model](#define_model)
|
| 70 |
+
- [objective](#objective)
|
| 71 |
+
- [start\_study](#start_study)
|
| 72 |
+
|
| 73 |
+
<a id="main"></a>
|
| 74 |
+
|
| 75 |
+
# main
|
| 76 |
+
|
| 77 |
+
<a id="PINN"></a>
|
| 78 |
+
|
| 79 |
+
# PINN
|
| 80 |
+
|
| 81 |
+
<a id="PINN.pinns"></a>
|
| 82 |
+
|
| 83 |
+
# PINN.pinns
|
| 84 |
+
|
| 85 |
+
<a id="PINN.pinns.PINNd_p"></a>
|
| 86 |
+
|
| 87 |
+
## PINNd\_p Objects
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
class PINNd_p(nn.Module)
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
$d \mapsto P$
|
| 94 |
+
|
| 95 |
+
<a id="PINN.pinns.PINNd_p.forward"></a>
|
| 96 |
+
|
| 97 |
+
#### forward
|
| 98 |
+
|
| 99 |
+
```python
|
| 100 |
+
def forward(x)
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
$P,U$ input, $d$ output
|
| 104 |
+
|
| 105 |
+
**Arguments**:
|
| 106 |
+
|
| 107 |
+
- `x` __type__ - _description_
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
**Returns**:
|
| 111 |
+
|
| 112 |
+
- `_type_` - _description_
|
| 113 |
+
|
| 114 |
+
<a id="PINN.pinns.PINNhd_ma"></a>
|
| 115 |
+
|
| 116 |
+
## PINNhd\_ma Objects
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
class PINNhd_ma(nn.Module)
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
$h,d \mapsto m_a $
|
| 123 |
+
|
| 124 |
+
<a id="PINN.pinns.PINNT_ma"></a>
|
| 125 |
+
|
| 126 |
+
## PINNT\_ma Objects
|
| 127 |
+
|
| 128 |
+
```python
|
| 129 |
+
class PINNT_ma(nn.Module)
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
$ m_a, U \mapsto T$
|
| 133 |
+
|
| 134 |
+
<a id="utils"></a>
|
| 135 |
+
|
| 136 |
+
# utils
|
| 137 |
+
|
| 138 |
+
<a id="utils.test"></a>
|
| 139 |
+
|
| 140 |
+
# utils.test
|
| 141 |
+
|
| 142 |
+
<a id="utils.dataset_loader"></a>
|
| 143 |
+
|
| 144 |
+
# utils.dataset\_loader
|
| 145 |
+
|
| 146 |
+
<a id="utils.dataset_loader.get_dataset"></a>
|
| 147 |
+
|
| 148 |
+
#### get\_dataset
|
| 149 |
+
|
| 150 |
+
```python
|
| 151 |
+
def get_dataset(raw: bool = False,
|
| 152 |
+
sample_size: int = 1000,
|
| 153 |
+
name: str = 'dataset.pkl',
|
| 154 |
+
source: str = 'dataset.csv',
|
| 155 |
+
boundary_conditions: list = None) -> _pickle
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
Gets augmented dataset
|
| 159 |
+
|
| 160 |
+
**Arguments**:
|
| 161 |
+
|
| 162 |
+
- `raw` _bool, optional_ - either to use source data or augmented. Defaults to False.
|
| 163 |
+
- `sample_size` _int, optional_ - sample size. Defaults to 1000.
|
| 164 |
+
- `name` _str, optional_ - name of wanted dataset. Defaults to 'dataset.pkl'.
|
| 165 |
+
- `boundary_conditions` _list,optional_ - y1,y2,x1,x2.
|
| 166 |
+
|
| 167 |
+
**Returns**:
|
| 168 |
+
|
| 169 |
+
- `_pickle` - pickle buffer
|
| 170 |
+
|
| 171 |
+
<a id="utils.ndgan"></a>
|
| 172 |
+
|
| 173 |
+
# utils.ndgan
|
| 174 |
+
|
| 175 |
+
<a id="utils.ndgan.DCGAN"></a>
|
| 176 |
+
|
| 177 |
+
## DCGAN Objects
|
| 178 |
+
|
| 179 |
+
```python
|
| 180 |
+
class DCGAN()
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
<a id="utils.ndgan.DCGAN.__init__"></a>
|
| 184 |
+
|
| 185 |
+
#### \_\_init\_\_
|
| 186 |
+
|
| 187 |
+
```python
|
| 188 |
+
def __init__(latent, data)
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
The function takes in two arguments, the latent space dimension and the dataframe. It then sets
|
| 192 |
+
|
| 193 |
+
the latent space dimension, the dataframe, the number of inputs and outputs, and then builds the
|
| 194 |
+
models
|
| 195 |
+
|
| 196 |
+
**Arguments**:
|
| 197 |
+
|
| 198 |
+
- `latent`: The number of dimensions in the latent space
|
| 199 |
+
- `data`: This is the dataframe that contains the data that we want to generate
|
| 200 |
+
|
| 201 |
+
<a id="utils.ndgan.DCGAN.define_discriminator"></a>
|
| 202 |
+
|
| 203 |
+
#### define\_discriminator
|
| 204 |
+
|
| 205 |
+
```python
|
| 206 |
+
def define_discriminator(inputs=8)
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
The discriminator is a neural network that takes in a vector of length 8 and outputs a single
|
| 210 |
+
|
| 211 |
+
value between 0 and 1
|
| 212 |
+
|
| 213 |
+
**Arguments**:
|
| 214 |
+
|
| 215 |
+
- `inputs`: number of features in the dataset, defaults to 8 (optional)
|
| 216 |
+
|
| 217 |
+
**Returns**:
|
| 218 |
+
|
| 219 |
+
The model is being returned.
|
| 220 |
+
|
| 221 |
+
<a id="utils.ndgan.DCGAN.define_generator"></a>
|
| 222 |
+
|
| 223 |
+
#### define\_generator
|
| 224 |
+
|
| 225 |
+
```python
|
| 226 |
+
def define_generator(latent_dim, outputs=8)
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
The function takes in a latent dimension and outputs and returns a model with two hidden layers
|
| 230 |
+
|
| 231 |
+
and an output layer
|
| 232 |
+
|
| 233 |
+
**Arguments**:
|
| 234 |
+
|
| 235 |
+
- `latent_dim`: The dimension of the latent space, or the space that the generator will map
|
| 236 |
+
to
|
| 237 |
+
- `outputs`: the number of outputs of the generator, defaults to 8 (optional)
|
| 238 |
+
|
| 239 |
+
**Returns**:
|
| 240 |
+
|
| 241 |
+
The model is being returned.
|
| 242 |
+
|
| 243 |
+
<a id="utils.ndgan.DCGAN.build_models"></a>
|
| 244 |
+
|
| 245 |
+
#### build\_models
|
| 246 |
+
|
| 247 |
+
```python
|
| 248 |
+
def build_models()
|
| 249 |
+
```
|
| 250 |
+
|
| 251 |
+
The function returns the generator and discriminator models
|
| 252 |
+
|
| 253 |
+
**Returns**:
|
| 254 |
+
|
| 255 |
+
The generator and discriminator models are being returned.
|
| 256 |
+
|
| 257 |
+
<a id="utils.ndgan.DCGAN.generate_latent_points"></a>
|
| 258 |
+
|
| 259 |
+
#### generate\_latent\_points
|
| 260 |
+
|
| 261 |
+
```python
|
| 262 |
+
def generate_latent_points(latent_dim, n)
|
| 263 |
+
```
|
| 264 |
+
|
| 265 |
+
> Generate random points in latent space as input for the generator
|
| 266 |
+
|
| 267 |
+
**Arguments**:
|
| 268 |
+
|
| 269 |
+
- `latent_dim`: the dimension of the latent space, which is the input to the generator
|
| 270 |
+
- `n`: number of images to generate
|
| 271 |
+
|
| 272 |
+
**Returns**:
|
| 273 |
+
|
| 274 |
+
A numpy array of random numbers.
|
| 275 |
+
|
| 276 |
+
<a id="utils.ndgan.DCGAN.generate_fake_samples"></a>
|
| 277 |
+
|
| 278 |
+
#### generate\_fake\_samples
|
| 279 |
+
|
| 280 |
+
```python
|
| 281 |
+
def generate_fake_samples(generator, latent_dim, n)
|
| 282 |
+
```
|
| 283 |
+
|
| 284 |
+
It generates a batch of fake samples with class labels
|
| 285 |
+
|
| 286 |
+
**Arguments**:
|
| 287 |
+
|
| 288 |
+
- `generator`: The generator model that we will train
|
| 289 |
+
- `latent_dim`: The dimension of the latent space, e.g. 100
|
| 290 |
+
- `n`: The number of samples to generate
|
| 291 |
+
|
| 292 |
+
**Returns**:
|
| 293 |
+
|
| 294 |
+
x is the generated images and y is the labels for the generated images.
|
| 295 |
+
|
| 296 |
+
<a id="utils.ndgan.DCGAN.define_gan"></a>
|
| 297 |
+
|
| 298 |
+
#### define\_gan
|
| 299 |
+
|
| 300 |
+
```python
|
| 301 |
+
def define_gan(generator, discriminator)
|
| 302 |
+
```
|
| 303 |
+
|
| 304 |
+
The function takes in a generator and a discriminator, sets the discriminator to be untrainable,
|
| 305 |
+
|
| 306 |
+
and then adds the generator and discriminator to a sequential model. The sequential model is then compiled with an optimizer and a loss function.
|
| 307 |
+
|
| 308 |
+
The optimizer is adam, which is a type of gradient descent algorithm.
|
| 309 |
+
|
| 310 |
+
Loss function is binary crossentropy, which is a loss function that is used for binary
|
| 311 |
+
classification problems.
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
The function then returns the GAN.
|
| 315 |
+
|
| 316 |
+
**Arguments**:
|
| 317 |
+
|
| 318 |
+
- `generator`: The generator model
|
| 319 |
+
- `discriminator`: The discriminator model that takes in a dataset and outputs a single value
|
| 320 |
+
representing fake/real
|
| 321 |
+
|
| 322 |
+
**Returns**:
|
| 323 |
+
|
| 324 |
+
The model is being returned.
|
| 325 |
+
|
| 326 |
+
<a id="utils.ndgan.DCGAN.summarize_performance"></a>
|
| 327 |
+
|
| 328 |
+
#### summarize\_performance
|
| 329 |
+
|
| 330 |
+
```python
|
| 331 |
+
def summarize_performance(epoch, generator, discriminator, latent_dim, n=200)
|
| 332 |
+
```
|
| 333 |
+
|
| 334 |
+
> This function evaluates the discriminator on real and fake data, and plots the real and fake
|
| 335 |
+
|
| 336 |
+
data
|
| 337 |
+
|
| 338 |
+
**Arguments**:
|
| 339 |
+
|
| 340 |
+
- `epoch`: the number of epochs to train for
|
| 341 |
+
- `generator`: the generator model
|
| 342 |
+
- `discriminator`: the discriminator model
|
| 343 |
+
- `latent_dim`: The dimension of the latent space
|
| 344 |
+
- `n`: number of samples to generate, defaults to 200 (optional)
|
| 345 |
+
|
| 346 |
+
<a id="utils.ndgan.DCGAN.train_gan"></a>
|
| 347 |
+
|
| 348 |
+
#### train\_gan
|
| 349 |
+
|
| 350 |
+
```python
|
| 351 |
+
def train_gan(g_model,
|
| 352 |
+
d_model,
|
| 353 |
+
gan_model,
|
| 354 |
+
latent_dim,
|
| 355 |
+
num_epochs=2500,
|
| 356 |
+
num_eval=2500,
|
| 357 |
+
batch_size=2)
|
| 358 |
+
```
|
| 359 |
+
|
| 360 |
+
**Arguments**:
|
| 361 |
+
|
| 362 |
+
- `g_model`: the generator model
|
| 363 |
+
- `d_model`: The discriminator model
|
| 364 |
+
- `gan_model`: The GAN model, which is the generator model combined with the discriminator
|
| 365 |
+
model
|
| 366 |
+
- `latent_dim`: The dimension of the latent space. This is the number of random numbers that
|
| 367 |
+
the generator model will take as input
|
| 368 |
+
- `num_epochs`: The number of epochs to train for, defaults to 2500 (optional)
|
| 369 |
+
- `num_eval`: number of epochs to run before evaluating the model, defaults to 2500
|
| 370 |
+
(optional)
|
| 371 |
+
- `batch_size`: The number of samples to use for each gradient update, defaults to 2
|
| 372 |
+
(optional)
|
| 373 |
+
|
| 374 |
+
<a id="utils.ndgan.DCGAN.start_training"></a>
|
| 375 |
+
|
| 376 |
+
#### start\_training
|
| 377 |
+
|
| 378 |
+
```python
|
| 379 |
+
def start_training()
|
| 380 |
+
```
|
| 381 |
+
|
| 382 |
+
The function takes the generator, discriminator, and gan models, and the latent vector as
|
| 383 |
+
arguments, and then calls the train_gan function.
|
| 384 |
+
|
| 385 |
+
<a id="utils.ndgan.DCGAN.predict"></a>
|
| 386 |
+
|
| 387 |
+
#### predict
|
| 388 |
+
|
| 389 |
+
```python
|
| 390 |
+
def predict(n)
|
| 391 |
+
```
|
| 392 |
+
|
| 393 |
+
It takes the generator model and the latent space as input and returns a batch of fake samples
|
| 394 |
+
|
| 395 |
+
**Arguments**:
|
| 396 |
+
|
| 397 |
+
- `n`: the number of samples to generate
|
| 398 |
+
|
| 399 |
+
**Returns**:
|
| 400 |
+
|
| 401 |
+
the generated fake samples.
|
| 402 |
+
|
| 403 |
+
<a id="utils.data_augmentation"></a>
|
| 404 |
+
|
| 405 |
+
# utils.data\_augmentation
|
| 406 |
+
|
| 407 |
+
<a id="utils.data_augmentation.dataset"></a>
|
| 408 |
+
|
| 409 |
+
## dataset Objects
|
| 410 |
+
|
| 411 |
+
```python
|
| 412 |
+
class dataset()
|
| 413 |
+
```
|
| 414 |
+
|
| 415 |
+
Creates dataset from input source
|
| 416 |
+
|
| 417 |
+
<a id="utils.data_augmentation.dataset.__init__"></a>
|
| 418 |
+
|
| 419 |
+
#### \_\_init\_\_
|
| 420 |
+
|
| 421 |
+
```python
|
| 422 |
+
def __init__(number_samples: int,
|
| 423 |
+
name: str,
|
| 424 |
+
source: str,
|
| 425 |
+
boundary_conditions: list = None)
|
| 426 |
+
```
|
| 427 |
+
|
| 428 |
+
|
| 429 |
+
**Arguments**:
|
| 430 |
+
|
| 431 |
+
- `number_samples` _int_ - number of samples to be genarated
|
| 432 |
+
- `name` _str_ - name of dataset
|
| 433 |
+
- `source` _str_ - source file
|
| 434 |
+
- `boundary_conditions` _list_ - y1,y2,x1,x2
|
| 435 |
+
|
| 436 |
+
<a id="utils.data_augmentation.dataset.generate"></a>
|
| 437 |
+
|
| 438 |
+
#### generate
|
| 439 |
+
|
| 440 |
+
```python
|
| 441 |
+
def generate()
|
| 442 |
+
```
|
| 443 |
+
|
| 444 |
+
The function takes in a dataframe, normalizes it, and then trains a DCGAN on it.
|
| 445 |
+
|
| 446 |
+
The DCGAN is a type of generative adversarial network (GAN) that is used to generate new data.
|
| 447 |
+
|
| 448 |
+
The DCGAN is trained on the normalized dataframe, and then the DCGAN is used to generate new
|
| 449 |
+
data.
|
| 450 |
+
|
| 451 |
+
The new data is then concatenated with the original dataframe, and the new dataframe is saved as
|
| 452 |
+
a pickle file.
|
| 453 |
+
|
| 454 |
+
The new dataframe is then returned.
|
| 455 |
+
|
| 456 |
+
**Returns**:
|
| 457 |
+
|
| 458 |
+
The dataframe is being returned.
|
| 459 |
+
|
| 460 |
+
<a id="nets"></a>
|
| 461 |
+
|
| 462 |
+
# :orange[nets]
|
| 463 |
+
|
| 464 |
+
<a id="nets.envs"></a>
|
| 465 |
+
|
| 466 |
+
# nets.envs
|
| 467 |
+
|
| 468 |
+
<a id="nets.envs.SCI"></a>
|
| 469 |
+
|
| 470 |
+
## SCI Objects
|
| 471 |
+
|
| 472 |
+
```python
|
| 473 |
+
class SCI()
|
| 474 |
+
```
|
| 475 |
+
|
| 476 |
+
Scaled computing interface.
|
| 477 |
+
|
| 478 |
+
**Arguments**:
|
| 479 |
+
|
| 480 |
+
- `hidden_dim` _int, optional_ - Max demension of hidden linear layer. Defaults to 200. Should be >80 in not 1d case
|
| 481 |
+
- `dropout` _bool, optional_ - LEGACY, don't use. Defaults to True.
|
| 482 |
+
- `epochs` _int, optional_ - Optionally specify epochs here, but better in train. Defaults to 10.
|
| 483 |
+
- `dataset` _str, optional_ - dataset to be selected from ./data. Defaults to 'test.pkl'. If name not exists, code will generate new dataset with upcoming parameters.
|
| 484 |
+
- `sample_size` _int, optional_ - Samples to be generated (note: BEFORE applying boundary conditions). Defaults to 1000.
|
| 485 |
+
- `source` _str, optional_ - Source from which data will be generated. Better to not change. Defaults to 'dataset.csv'.
|
| 486 |
+
- `boundary_conditions` _list, optional_ - If sepcified, whole dataset will be cut rectangulary. Input list is [ymin,ymax,xmin,xmax] type. Defaults to None.
|
| 487 |
+
|
| 488 |
+
<a id="nets.envs.SCI.__init__"></a>
|
| 489 |
+
|
| 490 |
+
#### \_\_init\_\_
|
| 491 |
+
|
| 492 |
+
```python
|
| 493 |
+
def __init__(hidden_dim: int = 200,
|
| 494 |
+
dropout: bool = True,
|
| 495 |
+
epochs: int = 10,
|
| 496 |
+
dataset: str = 'test.pkl',
|
| 497 |
+
sample_size: int = 1000,
|
| 498 |
+
source: str = 'dataset.csv',
|
| 499 |
+
boundary_conditions: list = None,
|
| 500 |
+
batch_size: int = 20)
|
| 501 |
+
```
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
**Arguments**:
|
| 506 |
+
|
| 507 |
+
- `hidden_dim` _int, optional_ - Max demension of hidden linear layer. Defaults to 200. Should be >80 in not 1d case
|
| 508 |
+
- `dropout` _bool, optional_ - LEGACY, don't use. Defaults to True.
|
| 509 |
+
- `epochs` _int, optional_ - Optionally specify epochs here, but better in train. Defaults to 10.
|
| 510 |
+
- `dataset` _str, optional_ - dataset to be selected from ./data. Defaults to 'test.pkl'. If name not exists, code will generate new dataset with upcoming parameters.
|
| 511 |
+
- `sample_size` _int, optional_ - Samples to be generated (note: BEFORE applying boundary conditions). Defaults to 1000.
|
| 512 |
+
- `source` _str, optional_ - Source from which data will be generated. Better to not change. Defaults to 'dataset.csv'.
|
| 513 |
+
- `boundary_conditions` _list, optional_ - If sepcified, whole dataset will be cut rectangulary. Input list is [ymin,ymax,xmin,xmax] type. Defaults to None.
|
| 514 |
+
- `batch_size` _int, optional_ - Batch size for training.
|
| 515 |
+
|
| 516 |
+
<a id="nets.envs.SCI.feature_gen"></a>
|
| 517 |
+
|
| 518 |
+
#### feature\_gen
|
| 519 |
+
|
| 520 |
+
```python
|
| 521 |
+
def feature_gen(base: bool = True,
|
| 522 |
+
fname: str = None,
|
| 523 |
+
index: int = None,
|
| 524 |
+
func=None) -> None
|
| 525 |
+
```
|
| 526 |
+
|
| 527 |
+
Generate new features. If base true, generates most obvious ones. You can customize this by adding
|
| 528 |
+
new feature as name of column - fname, index of parent column, and lambda function which needs to be applied elementwise.
|
| 529 |
+
|
| 530 |
+
**Arguments**:
|
| 531 |
+
|
| 532 |
+
- `base` _bool, optional_ - Defaults to True.
|
| 533 |
+
- `fname` _str, optional_ - Name of new column. Defaults to None.
|
| 534 |
+
- `index` _int, optional_ - Index of parent column. Defaults to None.
|
| 535 |
+
- `func` __type_, optional_ - lambda function. Defaults to None.
|
| 536 |
+
|
| 537 |
+
<a id="nets.envs.SCI.feature_importance"></a>
|
| 538 |
+
|
| 539 |
+
#### feature\_importance
|
| 540 |
+
|
| 541 |
+
```python
|
| 542 |
+
def feature_importance(X: pd.DataFrame, Y: pd.Series, verbose: int = 1)
|
| 543 |
+
```
|
| 544 |
+
|
| 545 |
+
Gets feature importance by SGD regression and score selection. Default threshold is 1.25*mean
|
| 546 |
+
input X as self.df.iloc[:,(columns of choice)]
|
| 547 |
+
Y as self.df.iloc[:,(column of choice)]
|
| 548 |
+
|
| 549 |
+
**Arguments**:
|
| 550 |
+
|
| 551 |
+
- `X` _pd.DataFrame_ - Builtin DataFrame
|
| 552 |
+
- `Y` _pd.Series_ - Builtin Series
|
| 553 |
+
- `verbose` _int, optional_ - either to or to not print actual report. Defaults to 1.
|
| 554 |
+
|
| 555 |
+
**Returns**:
|
| 556 |
+
|
| 557 |
+
Report (str)
|
| 558 |
+
|
| 559 |
+
<a id="nets.envs.SCI.data_flow"></a>
|
| 560 |
+
|
| 561 |
+
#### data\_flow
|
| 562 |
+
|
| 563 |
+
```python
|
| 564 |
+
def data_flow(columns_idx: tuple = (1, 3, 3, 5),
|
| 565 |
+
idx: tuple = None,
|
| 566 |
+
split_idx: int = 800) -> torch.utils.data.DataLoader
|
| 567 |
+
```
|
| 568 |
+
|
| 569 |
+
Data prep pipeline
|
| 570 |
+
It is called automatically, don't call it in your code.
|
| 571 |
+
|
| 572 |
+
**Arguments**:
|
| 573 |
+
|
| 574 |
+
- `columns_idx` _tuple, optional_ - Columns to be selected (sliced 1:2 3:4) for feature fitting. Defaults to (1,3,3,5).
|
| 575 |
+
- `idx` _tuple, optional_ - 2|3 indexes to be selected for feature fitting. Defaults to None. Use either idx or columns_idx (for F:R->R idx, for F:R->R2 columns_idx)
|
| 576 |
+
split_idx (int) : Index to split for training
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
**Returns**:
|
| 580 |
+
|
| 581 |
+
- `torch.utils.data.DataLoader` - Torch native dataloader
|
| 582 |
+
|
| 583 |
+
<a id="nets.envs.SCI.init_seed"></a>
|
| 584 |
+
|
| 585 |
+
#### init\_seed
|
| 586 |
+
|
| 587 |
+
```python
|
| 588 |
+
def init_seed(seed)
|
| 589 |
+
```
|
| 590 |
+
|
| 591 |
+
Initializes seed for torch - optional
|
| 592 |
+
|
| 593 |
+
<a id="nets.envs.SCI.train_epoch"></a>
|
| 594 |
+
|
| 595 |
+
#### train\_epoch
|
| 596 |
+
|
| 597 |
+
```python
|
| 598 |
+
def train_epoch(X, model, loss_function, optim)
|
| 599 |
+
```
|
| 600 |
+
|
| 601 |
+
Inner function of class - don't use.
|
| 602 |
+
|
| 603 |
+
We iterate through the data, calculate the loss, backpropagate, and update the weights
|
| 604 |
+
|
| 605 |
+
**Arguments**:
|
| 606 |
+
|
| 607 |
+
- `X`: the training data
|
| 608 |
+
- `model`: the model we're training
|
| 609 |
+
- `loss_function`: the loss function to use
|
| 610 |
+
- `optim`: the optimizer, which is the algorithm that will update the weights of the model
|
| 611 |
+
|
| 612 |
+
<a id="nets.envs.SCI.compile"></a>
|
| 613 |
+
|
| 614 |
+
#### compile
|
| 615 |
+
|
| 616 |
+
```python
|
| 617 |
+
def compile(columns: tuple = None,
|
| 618 |
+
idx: tuple = None,
|
| 619 |
+
optim: torch.optim = torch.optim.AdamW,
|
| 620 |
+
loss: nn = nn.L1Loss,
|
| 621 |
+
model: nn.Module = dmodel,
|
| 622 |
+
custom: bool = False,
|
| 623 |
+
lr: float = 0.0001) -> None
|
| 624 |
+
```
|
| 625 |
+
|
| 626 |
+
Builds model, loss, optimizer. Has defaults
|
| 627 |
+
|
| 628 |
+
**Arguments**:
|
| 629 |
+
|
| 630 |
+
- `columns` _tuple, optional_ - Columns to be selected for feature fitting. Defaults to (1,3,3,5).
|
| 631 |
+
- `optim` - torch Optimizer. Default AdamW
|
| 632 |
+
- `loss` - torch Loss function (nn). Defaults to L1Loss
|
| 633 |
+
|
| 634 |
+
<a id="nets.envs.SCI.train"></a>
|
| 635 |
+
|
| 636 |
+
#### train
|
| 637 |
+
|
| 638 |
+
```python
|
| 639 |
+
def train(epochs: int = 10) -> None
|
| 640 |
+
```
|
| 641 |
+
|
| 642 |
+
Train model
|
| 643 |
+
- If sklearn instance uses .fit()
|
| 644 |
+
|
| 645 |
+
- epochs (int,optional)
|
| 646 |
+
|
| 647 |
+
<a id="nets.envs.SCI.save"></a>
|
| 648 |
+
|
| 649 |
+
#### save
|
| 650 |
+
|
| 651 |
+
```python
|
| 652 |
+
def save(name: str = 'model.pt') -> None
|
| 653 |
+
```
|
| 654 |
+
|
| 655 |
+
> This function saves the model to a file
|
| 656 |
+
|
| 657 |
+
**Arguments**:
|
| 658 |
+
|
| 659 |
+
- `name` (`str (optional)`): The name of the file to save the model to, defaults to model.pt
|
| 660 |
+
|
| 661 |
+
<a id="nets.envs.SCI.onnx_export"></a>
|
| 662 |
+
|
| 663 |
+
#### onnx\_export
|
| 664 |
+
|
| 665 |
+
```python
|
| 666 |
+
def onnx_export(path: str = './models/model.onnx')
|
| 667 |
+
```
|
| 668 |
+
|
| 669 |
+
> We are exporting the model to the ONNX format, using the input data and the model itself
|
| 670 |
+
|
| 671 |
+
**Arguments**:
|
| 672 |
+
|
| 673 |
+
- `path` (`str (optional)`): The path to save the model to, defaults to ./models/model.onnx
|
| 674 |
+
|
| 675 |
+
<a id="nets.envs.SCI.jit_export"></a>
|
| 676 |
+
|
| 677 |
+
#### jit\_export
|
| 678 |
+
|
| 679 |
+
```python
|
| 680 |
+
def jit_export(path: str = './models/model.pt')
|
| 681 |
+
```
|
| 682 |
+
|
| 683 |
+
Exports properly defined model to jit
|
| 684 |
+
|
| 685 |
+
**Arguments**:
|
| 686 |
+
|
| 687 |
+
- `path` _str, optional_ - path to models. Defaults to './models/model.pt'.
|
| 688 |
+
|
| 689 |
+
<a id="nets.envs.SCI.inference"></a>
|
| 690 |
+
|
| 691 |
+
#### inference
|
| 692 |
+
|
| 693 |
+
```python
|
| 694 |
+
def inference(X: tensor, model_name: str = None) -> np.ndarray
|
| 695 |
+
```
|
| 696 |
+
|
| 697 |
+
Inference of (pre-)trained model
|
| 698 |
+
|
| 699 |
+
**Arguments**:
|
| 700 |
+
|
| 701 |
+
- `X` _tensor_ - your data in domain of train
|
| 702 |
+
|
| 703 |
+
**Returns**:
|
| 704 |
+
|
| 705 |
+
- `np.ndarray` - predictions
|
| 706 |
+
|
| 707 |
+
<a id="nets.envs.SCI.plot"></a>
|
| 708 |
+
|
| 709 |
+
#### plot
|
| 710 |
+
|
| 711 |
+
```python
|
| 712 |
+
def plot()
|
| 713 |
+
```
|
| 714 |
+
|
| 715 |
+
> If the input and output dimensions are the same, plot the input and output as a scatter plot.
|
| 716 |
+
If the input and output dimensions are different, plot the first dimension of the input and
|
| 717 |
+
output as a scatter plot
|
| 718 |
+
|
| 719 |
+
<a id="nets.envs.SCI.plot3d"></a>
|
| 720 |
+
|
| 721 |
+
#### plot3d
|
| 722 |
+
|
| 723 |
+
```python
|
| 724 |
+
def plot3d(colX=0, colY=1)
|
| 725 |
+
```
|
| 726 |
+
|
| 727 |
+
Plot of inputs and predicted data in mesh format
|
| 728 |
+
|
| 729 |
+
**Returns**:
|
| 730 |
+
|
| 731 |
+
plotly plot
|
| 732 |
+
|
| 733 |
+
<a id="nets.envs.SCI.performance"></a>
|
| 734 |
+
|
| 735 |
+
#### performance
|
| 736 |
+
|
| 737 |
+
```python
|
| 738 |
+
def performance(c=0.4) -> dict
|
| 739 |
+
```
|
| 740 |
+
|
| 741 |
+
Automatic APE based performance if applicable, else returns nan
|
| 742 |
+
|
| 743 |
+
**Arguments**:
|
| 744 |
+
|
| 745 |
+
- `c` _float, optional_ - ZDE mitigation constant. Defaults to 0.4.
|
| 746 |
+
|
| 747 |
+
**Returns**:
|
| 748 |
+
|
| 749 |
+
- `dict` - {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 750 |
+
|
| 751 |
+
<a id="nets.envs.SCI.performance_super"></a>
|
| 752 |
+
|
| 753 |
+
#### performance\_super
|
| 754 |
+
|
| 755 |
+
```python
|
| 756 |
+
def performance_super(c=0.4,
|
| 757 |
+
real_data_column_index: tuple = (1, 8),
|
| 758 |
+
real_data_samples: int = 23,
|
| 759 |
+
generated_length: int = 1000) -> dict
|
| 760 |
+
```
|
| 761 |
+
|
| 762 |
+
Performance by custom parameters. APE loss
|
| 763 |
+
|
| 764 |
+
**Arguments**:
|
| 765 |
+
|
| 766 |
+
- `c` _float, optional_ - ZDE mitigation constant. Defaults to 0.4.
|
| 767 |
+
- `real_data_column_index` _tuple, optional_ - Defaults to (1,8).
|
| 768 |
+
- `real_data_samples` _int, optional_ - Defaults to 23.
|
| 769 |
+
- `generated_length` _int, optional_ - Defaults to 1000.
|
| 770 |
+
|
| 771 |
+
**Returns**:
|
| 772 |
+
|
| 773 |
+
- `dict` - {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 774 |
+
|
| 775 |
+
<a id="nets.envs.RCI"></a>
|
| 776 |
+
|
| 777 |
+
## RCI Objects
|
| 778 |
+
|
| 779 |
+
```python
|
| 780 |
+
class RCI(SCI)
|
| 781 |
+
```
|
| 782 |
+
|
| 783 |
+
Real values interface, uses different types of NN, NO scaling.
|
| 784 |
+
Parent:
|
| 785 |
+
SCI()
|
| 786 |
+
|
| 787 |
+
<a id="nets.envs.RCI.data_flow"></a>
|
| 788 |
+
|
| 789 |
+
#### data\_flow
|
| 790 |
+
|
| 791 |
+
```python
|
| 792 |
+
def data_flow(columns_idx: tuple = (1, 3, 3, 5),
|
| 793 |
+
idx: tuple = None,
|
| 794 |
+
split_idx: int = 800) -> torch.utils.data.DataLoader
|
| 795 |
+
```
|
| 796 |
+
|
| 797 |
+
Data prep pipeline
|
| 798 |
+
|
| 799 |
+
**Arguments**:
|
| 800 |
+
|
| 801 |
+
- `columns_idx` _tuple, optional_ - Columns to be selected (sliced 1:2 3:4) for feature fitting. Defaults to (1,3,3,5).
|
| 802 |
+
- `idx` _tuple, optional_ - 2|3 indexes to be selected for feature fitting. Defaults to None. Use either idx or columns_idx (for F:R->R idx, for F:R->R2 columns_idx)
|
| 803 |
+
split_idx (int) : Index to split for training
|
| 804 |
+
|
| 805 |
+
|
| 806 |
+
**Returns**:
|
| 807 |
+
|
| 808 |
+
- `torch.utils.data.DataLoader` - Torch native dataloader
|
| 809 |
+
|
| 810 |
+
<a id="nets.envs.RCI.compile"></a>
|
| 811 |
+
|
| 812 |
+
#### compile
|
| 813 |
+
|
| 814 |
+
```python
|
| 815 |
+
def compile(columns: tuple = None,
|
| 816 |
+
idx: tuple = (3, 1),
|
| 817 |
+
optim: torch.optim = torch.optim.AdamW,
|
| 818 |
+
loss: nn = nn.L1Loss,
|
| 819 |
+
model: nn.Module = PINNd_p,
|
| 820 |
+
lr: float = 0.001) -> None
|
| 821 |
+
```
|
| 822 |
+
|
| 823 |
+
Builds model, loss, optimizer. Has defaults
|
| 824 |
+
|
| 825 |
+
**Arguments**:
|
| 826 |
+
|
| 827 |
+
- `columns` _tuple, optional_ - Columns to be selected for feature fitting. Defaults to None.
|
| 828 |
+
- `idx` _tuple, optional_ - indexes to be selected Default (3,1)
|
| 829 |
+
optim - torch Optimizer
|
| 830 |
+
loss - torch Loss function (nn)
|
| 831 |
+
|
| 832 |
+
<a id="nets.envs.RCI.plot"></a>
|
| 833 |
+
|
| 834 |
+
#### plot
|
| 835 |
+
|
| 836 |
+
```python
|
| 837 |
+
def plot()
|
| 838 |
+
```
|
| 839 |
+
|
| 840 |
+
Plots 2d plot of prediction vs real values
|
| 841 |
+
|
| 842 |
+
<a id="nets.envs.RCI.performance"></a>
|
| 843 |
+
|
| 844 |
+
#### performance
|
| 845 |
+
|
| 846 |
+
```python
|
| 847 |
+
def performance(c=0.4) -> dict
|
| 848 |
+
```
|
| 849 |
+
|
| 850 |
+
RCI performnace. APE errors.
|
| 851 |
+
|
| 852 |
+
**Arguments**:
|
| 853 |
+
|
| 854 |
+
- `c` _float, optional_ - correction constant to mitigate division by 0 error. Defaults to 0.4.
|
| 855 |
+
|
| 856 |
+
**Returns**:
|
| 857 |
+
|
| 858 |
+
- `dict` - {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 859 |
+
|
| 860 |
+
<a id="nets.dense"></a>
|
| 861 |
+
|
| 862 |
+
# nets.dense
|
| 863 |
+
|
| 864 |
+
<a id="nets.dense.Net"></a>
|
| 865 |
+
|
| 866 |
+
## Net Objects
|
| 867 |
+
|
| 868 |
+
```python
|
| 869 |
+
class Net(nn.Module)
|
| 870 |
+
```
|
| 871 |
+
|
| 872 |
+
The Net class inherits from the nn.Module class, which has a number of attributes and methods (such
|
| 873 |
+
as .parameters() and .zero_grad()) which we will be using. You can read more about the nn.Module
|
| 874 |
+
class [here](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)
|
| 875 |
+
|
| 876 |
+
<a id="nets.dense.Net.__init__"></a>
|
| 877 |
+
|
| 878 |
+
#### \_\_init\_\_
|
| 879 |
+
|
| 880 |
+
```python
|
| 881 |
+
def __init__(input_dim: int = 2, hidden_dim: int = 200)
|
| 882 |
+
```
|
| 883 |
+
|
| 884 |
+
We create a neural network with two hidden layers, each with **hidden_dim** neurons, and a ReLU activation
|
| 885 |
+
|
| 886 |
+
function. The output layer has one neuron and no activation function
|
| 887 |
+
|
| 888 |
+
**Arguments**:
|
| 889 |
+
|
| 890 |
+
- `input_dim` (`int (optional)`): The dimension of the input, defaults to 2
|
| 891 |
+
- `hidden_dim` (`int (optional)`): The number of neurons in the hidden layer, defaults to 200
|
| 892 |
+
|
| 893 |
+
<a id="nets.design"></a>
|
| 894 |
+
|
| 895 |
+
# nets.design
|
| 896 |
+
|
| 897 |
+
<a id="nets.design.B_field_norm"></a>
|
| 898 |
+
|
| 899 |
+
#### B\_field\_norm
|
| 900 |
+
|
| 901 |
+
```python
|
| 902 |
+
def B_field_norm(Bmax: float, L: float, k: int = 16, plot=True) -> np.array
|
| 903 |
+
```
|
| 904 |
+
|
| 905 |
+
Returns vec B_z for MS config
|
| 906 |
+
|
| 907 |
+
**Arguments**:
|
| 908 |
+
|
| 909 |
+
- `Bmax` _any_ - maximum B in thruster
|
| 910 |
+
L - channel length
|
| 911 |
+
k - magnetic field profile number
|
| 912 |
+
|
| 913 |
+
<a id="nets.design.PUdesign"></a>
|
| 914 |
+
|
| 915 |
+
#### PUdesign
|
| 916 |
+
|
| 917 |
+
```python
|
| 918 |
+
def PUdesign(P: float, U: float) -> pd.DataFrame
|
| 919 |
+
```
|
| 920 |
+
|
| 921 |
+
Computes design via numerical model, uses fits from PINNs
|
| 922 |
+
|
| 923 |
+
**Arguments**:
|
| 924 |
+
|
| 925 |
+
- `P` _float_ - _description_
|
| 926 |
+
- `U` _float_ - _description_
|
| 927 |
+
|
| 928 |
+
|
| 929 |
+
**Returns**:
|
| 930 |
+
|
| 931 |
+
- `_type_` - _description_
|
| 932 |
+
|
| 933 |
+
<a id="nets.deep_dense"></a>
|
| 934 |
+
|
| 935 |
+
# nets.deep\_dense
|
| 936 |
+
|
| 937 |
+
<a id="nets.deep_dense.dmodel"></a>
|
| 938 |
+
|
| 939 |
+
## dmodel Objects
|
| 940 |
+
|
| 941 |
+
```python
|
| 942 |
+
class dmodel(nn.Module)
|
| 943 |
+
```
|
| 944 |
+
|
| 945 |
+
<a id="nets.deep_dense.dmodel.__init__"></a>
|
| 946 |
+
|
| 947 |
+
#### \_\_init\_\_
|
| 948 |
+
|
| 949 |
+
```python
|
| 950 |
+
def __init__(in_features=1, hidden_features=200, out_features=1)
|
| 951 |
+
```
|
| 952 |
+
|
| 953 |
+
We're creating a neural network with 4 layers, each with 200 neurons. The first layer takes in the input, the second layer takes in the output of the first layer, the third layer takes in the
|
| 954 |
+
output of the second layer, and the fourth layer takes in the output of the third layer
|
| 955 |
+
|
| 956 |
+
**Arguments**:
|
| 957 |
+
|
| 958 |
+
- `in_features`: The number of input features, defaults to 1 (optional)
|
| 959 |
+
- `hidden_features`: the number of neurons in the hidden layers, defaults to 200 (optional)
|
| 960 |
+
- `out_features`: The number of classes for classification (1 for regression), defaults to 1
|
| 961 |
+
(optional)
|
| 962 |
+
|
| 963 |
+
<a id="nets.opti"></a>
|
| 964 |
+
|
| 965 |
+
# nets.opti
|
| 966 |
+
|
| 967 |
+
<a id="nets.opti.blackbox"></a>
|
| 968 |
+
|
| 969 |
+
# nets.opti.blackbox
|
| 970 |
+
|
| 971 |
+
<a id="nets.opti.blackbox.Hyper"></a>
|
| 972 |
+
|
| 973 |
+
## Hyper Objects
|
| 974 |
+
|
| 975 |
+
```python
|
| 976 |
+
class Hyper(SCI)
|
| 977 |
+
```
|
| 978 |
+
|
| 979 |
+
Hyper parameter tunning class. Allows to generate best NN architecture for task. Inputs are column indexes. idx[-1] is targeted value.
|
| 980 |
+
Based on OPTUNA algorithms it is very fast and reliable. Outputs are NN parameters in json. Optionally full report for every trial is available at the neptune.ai
|
| 981 |
+
|
| 982 |
+
<a id="nets.opti.blackbox.Hyper.__init__"></a>
|
| 983 |
+
|
| 984 |
+
#### \_\_init\_\_
|
| 985 |
+
|
| 986 |
+
```python
|
| 987 |
+
def __init__(idx: tuple = (1, 3, 7), *args, **kwargs)
|
| 988 |
+
```
|
| 989 |
+
|
| 990 |
+
The function __init__() is a constructor that initializes the class Hyper
|
| 991 |
+
|
| 992 |
+
**Arguments**:
|
| 993 |
+
|
| 994 |
+
- `idx` (`tuple`): tuple of integers, the indices of the data to be loaded
|
| 995 |
+
|
| 996 |
+
<a id="nets.opti.blackbox.Hyper.define_model"></a>
|
| 997 |
+
|
| 998 |
+
#### define\_model
|
| 999 |
+
|
| 1000 |
+
```python
|
| 1001 |
+
def define_model(trial)
|
| 1002 |
+
```
|
| 1003 |
+
|
| 1004 |
+
We define a function that takes in a trial object and returns a neural network with the number
|
| 1005 |
+
|
| 1006 |
+
of layers, hidden units and activation functions defined by the trial object.
|
| 1007 |
+
|
| 1008 |
+
**Arguments**:
|
| 1009 |
+
|
| 1010 |
+
- `trial`: This is an object that contains the information about the current trial
|
| 1011 |
+
|
| 1012 |
+
**Returns**:
|
| 1013 |
+
|
| 1014 |
+
A sequential model with the number of layers, hidden units and activation functions
|
| 1015 |
+
defined by the trial.
|
| 1016 |
+
|
| 1017 |
+
<a id="nets.opti.blackbox.Hyper.objective"></a>
|
| 1018 |
+
|
| 1019 |
+
#### objective
|
| 1020 |
+
|
| 1021 |
+
```python
|
| 1022 |
+
def objective(trial)
|
| 1023 |
+
```
|
| 1024 |
+
|
| 1025 |
+
We define a model, an optimizer, and a loss function. We then train the model for a number of
|
| 1026 |
+
|
| 1027 |
+
epochs, and report the loss at the end of each epoch
|
| 1028 |
+
|
| 1029 |
+
*"optimizer": ["Adam", "RMSprop", "SGD" 'AdamW','Adamax','Adagrad']*
|
| 1030 |
+
*"lr" $\in$ [1e-7,1e-3], log=True*
|
| 1031 |
+
|
| 1032 |
+
**Arguments**:
|
| 1033 |
+
|
| 1034 |
+
- `trial`: The trial object that is passed to the objective function
|
| 1035 |
+
|
| 1036 |
+
**Returns**:
|
| 1037 |
+
|
| 1038 |
+
The accuracy of the model.
|
| 1039 |
+
|
| 1040 |
+
<a id="nets.opti.blackbox.Hyper.start_study"></a>
|
| 1041 |
+
|
| 1042 |
+
#### start\_study
|
| 1043 |
+
|
| 1044 |
+
```python
|
| 1045 |
+
def start_study(n_trials: int = 100,
|
| 1046 |
+
neptune_project: str = None,
|
| 1047 |
+
neptune_api: str = None)
|
| 1048 |
+
```
|
| 1049 |
+
|
| 1050 |
+
It takes a number of trials, a neptune project name and a neptune api token as input and runs
|
| 1051 |
+
|
| 1052 |
+
the objective function on the number of trials specified. If the neptune project and api token
|
| 1053 |
+
are provided, it logs the results to neptune
|
| 1054 |
+
|
| 1055 |
+
**Arguments**:
|
| 1056 |
+
|
| 1057 |
+
- `n_trials` (`int (optional)`): The number of trials to run, defaults to 100
|
| 1058 |
+
- `neptune_project` (`str`): the name of the neptune project you want to log to
|
| 1059 |
+
- `neptune_api` (`str`): your neptune api key
|
| 1060 |
+
|
main.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
from nets.envs import SCI
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
st.set_page_config(
|
| 7 |
+
page_title="HET_sci",
|
| 8 |
+
menu_items={
|
| 9 |
+
'About':'https://advpropsys.github.io'
|
| 10 |
+
}
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
st.title('HETfit_scientific')
|
| 14 |
+
st.markdown("#### Imagine a package which was engineered primarly for data driven plasma physics devices design, mainly low power hall effect thrusters, yup that's it"
|
| 15 |
+
"\n### :orange[Don't be scared away though, it has much simpler interface than anything you ever used for such designs]")
|
| 16 |
+
st.markdown('### Main concepts:')
|
| 17 |
+
st.markdown( "- Each observational/design session is called an **environment**, for now it can be either RCI or SCI (Real or scaled interface)"
|
| 18 |
+
"\n In this overview we will only touch SCI, since RCI is using PINNs which are different topic"
|
| 19 |
+
"\n- You specify most of the run parameters on this object init, :orange[**including generation of new samples**] via GAN"
|
| 20 |
+
"\n- You may want to generate new features, do it !"
|
| 21 |
+
"\n- Want to select best features for more effctive work? Done!"
|
| 22 |
+
"\n- Compile environment with your model of choice, can be ***any*** torch model or sklearn one"
|
| 23 |
+
"\n- Train !"
|
| 24 |
+
"\n- Plot, inference, save, export to jit/onnx, measure performance - **they all are one liners** "
|
| 25 |
+
)
|
| 26 |
+
st.markdown('### tl;dr \n- Create environment'
|
| 27 |
+
'\n```run = SCI(*args,**kwargs)```'
|
| 28 |
+
'\n - Generate features ```run.feature_gen()``` '
|
| 29 |
+
'\n - Select features ```run.feature_importance()```'
|
| 30 |
+
'\n - Compile env ```run.compile()```'
|
| 31 |
+
'\n - Train model in env ```run.train()```'
|
| 32 |
+
'\n - Inference, plot, performance, ex. ```run.plot3d()```'
|
| 33 |
+
'\n #### And yes, it all will work even without any additional arguments from user besides column indexes'
|
| 34 |
+
)
|
| 35 |
+
st.write('Comparison with *arXiv:2206.04440v3*')
|
| 36 |
+
col1, col2 = st.columns(2)
|
| 37 |
+
col1.metric('Geometry accuracy on domain',value='83%',delta='15%')
|
| 38 |
+
col2.metric('$d \mapsto h$ prediction',value='98%',delta='14%')
|
| 39 |
+
|
| 40 |
+
st.header('Example:')
|
| 41 |
+
|
| 42 |
+
st.markdown('Remeber indexes and column names on this example: $P$ - 1, $d$ - 3, $h$ - 3, $m_a$ - 6,$T$ - 7')
|
| 43 |
+
st.code('run = SCI(*args,**kwargs)')
|
| 44 |
+
|
| 45 |
+
run = SCI()
|
| 46 |
+
st.code('run.feature_gen()')
|
| 47 |
+
run.feature_gen()
|
| 48 |
+
st.write('New features: (index-0:22 original samples, else is GAN generated)',run.df.iloc[1:,9:].astype(float))
|
| 49 |
+
st.write('Most of real dataset is from *doi:0.2514/1.B37424*, hence the results mostly agree with it in specific')
|
| 50 |
+
st.code('run.feature_importance(run.df.iloc[1:,1:7].astype(float),run.df.iloc[1:,7]) # Clear and easy example')
|
| 51 |
+
|
| 52 |
+
st.write(run.feature_importance(run.df.iloc[1:,1:6].astype(float),run.df.iloc[1:,6]))
|
| 53 |
+
st.markdown(' As we can see only $h$ and $d$ passed for $m_a$ model, not only that linear dependacy was proven experimantally, but now we got this from data driven source')
|
| 54 |
+
st.code('run.compile(idx=(1,3,7))')
|
| 55 |
+
run.compile(idx=(1,3,7))
|
| 56 |
+
st.code('run.train(epochs=10)')
|
| 57 |
+
if st.button('Start Training⏳',use_container_width=True):
|
| 58 |
+
run.train(epochs=10)
|
| 59 |
+
st.code('run.plot3d()')
|
| 60 |
+
st.write(run.plot3d())
|
| 61 |
+
st.code('run.performance()')
|
| 62 |
+
st.write(run.performance())
|
| 63 |
+
else:
|
| 64 |
+
st.markdown('#')
|
| 65 |
+
|
| 66 |
+
st.markdown('---\nTry it out yourself! Select a column from 1 to 10')
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
number = st.number_input('Here',min_value=1, max_value=10, step=1)
|
| 70 |
+
|
| 71 |
+
if number:
|
| 72 |
+
if st.button('Compile And Train💅',use_container_width=True):
|
| 73 |
+
st.code(f'run.compile(idx=(1,3,{number}))')
|
| 74 |
+
run.compile(idx=(1,3,number))
|
| 75 |
+
st.code('run.train(epochs=10)')
|
| 76 |
+
run.train(epochs=10)
|
| 77 |
+
st.code('run.plot3d()')
|
| 78 |
+
st.write(run.plot3d())
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
st.markdown('In this intro we covered simplest userflow while using HETFit package, resulted data can be used to leverage PINN and analytical models of Hall effect thrusters'
|
| 83 |
+
'\n #### :orange[To cite please contact author on https://github.com/advpropsys]')
|
model.png
ADDED

|
models/model.onnx
ADDED
|
Binary file (80.2 kB). View file
|
|
|
module_name.md
ADDED
|
@@ -0,0 +1,456 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Table of Contents
|
| 2 |
+
|
| 3 |
+
- [Table of Contents](#table-of-contents)
|
| 4 |
+
- [main](#main)
|
| 5 |
+
- [:orange\[PINN\]](#orangepinn)
|
| 6 |
+
- [PINN.pinns](#pinnpinns)
|
| 7 |
+
- [PINNd\_p Objects](#pinnd_p-objects)
|
| 8 |
+
- [PINNhd\_ma Objects](#pinnhd_ma-objects)
|
| 9 |
+
- [PINNT\_ma Objects](#pinnt_ma-objects)
|
| 10 |
+
- [:orange\[utils\]](#orangeutils)
|
| 11 |
+
- [utils.test](#utilstest)
|
| 12 |
+
- [utils.dataset\_loader](#utilsdataset_loader)
|
| 13 |
+
- [get\_dataset](#get_dataset)
|
| 14 |
+
- [utils.ndgan](#utilsndgan)
|
| 15 |
+
- [DCGAN Objects](#dcgan-objects)
|
| 16 |
+
- [define\_discriminator](#define_discriminator)
|
| 17 |
+
- [generate\_latent\_points](#generate_latent_points)
|
| 18 |
+
- [define\_gan](#define_gan)
|
| 19 |
+
- [summarize\_performance](#summarize_performance)
|
| 20 |
+
- [train\_gan](#train_gan)
|
| 21 |
+
- [utils.data\_augmentation](#utilsdata_augmentation)
|
| 22 |
+
- [dataset Objects](#dataset-objects)
|
| 23 |
+
- [\_\_init\_\_](#__init__)
|
| 24 |
+
- [:orange\[nets\]](#orangenets)
|
| 25 |
+
- [nets.envs](#netsenvs)
|
| 26 |
+
- [SCI Objects](#sci-objects)
|
| 27 |
+
- [data\_flow](#data_flow)
|
| 28 |
+
- [init\_seed](#init_seed)
|
| 29 |
+
- [compile](#compile)
|
| 30 |
+
- [train](#train)
|
| 31 |
+
- [inference](#inference)
|
| 32 |
+
- [RCI Objects](#rci-objects)
|
| 33 |
+
- [data\_flow](#data_flow-1)
|
| 34 |
+
- [compile](#compile-1)
|
| 35 |
+
- [nets.dense](#netsdense)
|
| 36 |
+
- [Net Objects](#net-objects)
|
| 37 |
+
- [\_\_init\_\_](#__init__-1)
|
| 38 |
+
- [nets.design](#netsdesign)
|
| 39 |
+
- [B\_field\_norm](#b_field_norm)
|
| 40 |
+
- [nets.deep\_dense](#netsdeep_dense)
|
| 41 |
+
- [dmodel Objects](#dmodel-objects)
|
| 42 |
+
- [\_\_init\_\_](#__init__-2)
|
| 43 |
+
|
| 44 |
+
<a id="main"></a>
|
| 45 |
+
|
| 46 |
+
# main
|
| 47 |
+
|
| 48 |
+
<a id="PINN"></a>
|
| 49 |
+
|
| 50 |
+
# :orange[PINN]
|
| 51 |
+
|
| 52 |
+
<a id="PINN.pinns"></a>
|
| 53 |
+
|
| 54 |
+
## PINN.pinns
|
| 55 |
+
|
| 56 |
+
<a id="PINN.pinns.PINNd_p"></a>
|
| 57 |
+
|
| 58 |
+
## PINNd\_p Objects
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
class PINNd_p(nn.Module)
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
$d \mapsto P$
|
| 65 |
+
|
| 66 |
+
<a id="PINN.pinns.PINNhd_ma"></a>
|
| 67 |
+
|
| 68 |
+
## PINNhd\_ma Objects
|
| 69 |
+
|
| 70 |
+
```python
|
| 71 |
+
class PINNhd_ma(nn.Module)
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
$h,d \mapsto m_a $
|
| 75 |
+
|
| 76 |
+
<a id="PINN.pinns.PINNT_ma"></a>
|
| 77 |
+
|
| 78 |
+
## PINNT\_ma Objects
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
class PINNT_ma(nn.Module)
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
$ m_a, U \mapsto T$
|
| 85 |
+
|
| 86 |
+
<a id="utils"></a>
|
| 87 |
+
|
| 88 |
+
---
|
| 89 |
+
# :orange[utils]
|
| 90 |
+
|
| 91 |
+
<a id="utils.test"></a>
|
| 92 |
+
|
| 93 |
+
## utils.test
|
| 94 |
+
|
| 95 |
+
<a id="utils.dataset_loader"></a>
|
| 96 |
+
|
| 97 |
+
## utils.dataset\_loader
|
| 98 |
+
|
| 99 |
+
<a id="utils.dataset_loader.get_dataset"></a>
|
| 100 |
+
|
| 101 |
+
#### get\_dataset
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
def get_dataset(raw: bool = False,
|
| 105 |
+
sample_size: int = 1000,
|
| 106 |
+
name: str = 'dataset.pkl',
|
| 107 |
+
source: str = 'dataset.csv',
|
| 108 |
+
boundary_conditions: list = None) -> _pickle
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
Gets augmented dataset
|
| 112 |
+
|
| 113 |
+
**Arguments**:
|
| 114 |
+
|
| 115 |
+
- `raw` _bool, optional_ - either to use source data or augmented. Defaults to False.
|
| 116 |
+
- `sample_size` _int, optional_ - sample size. Defaults to 1000.
|
| 117 |
+
- `name` _str, optional_ - name of wanted dataset. Defaults to 'dataset.pkl'.
|
| 118 |
+
- `boundary_conditions` _list,optional_ - y1,y2,x1,x2.
|
| 119 |
+
|
| 120 |
+
**Returns**:
|
| 121 |
+
|
| 122 |
+
- `_pickle` - pickle buffer
|
| 123 |
+
|
| 124 |
+
<a id="utils.ndgan"></a>
|
| 125 |
+
|
| 126 |
+
## utils.ndgan
|
| 127 |
+
|
| 128 |
+
<a id="utils.ndgan.DCGAN"></a>
|
| 129 |
+
|
| 130 |
+
### DCGAN Objects
|
| 131 |
+
|
| 132 |
+
```python
|
| 133 |
+
class DCGAN()
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
<a id="utils.ndgan.DCGAN.define_discriminator"></a>
|
| 137 |
+
|
| 138 |
+
#### define\_discriminator
|
| 139 |
+
|
| 140 |
+
```python
|
| 141 |
+
def define_discriminator(inputs=8)
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
function to return the compiled discriminator model
|
| 145 |
+
|
| 146 |
+
<a id="utils.ndgan.DCGAN.generate_latent_points"></a>
|
| 147 |
+
|
| 148 |
+
#### generate\_latent\_points
|
| 149 |
+
|
| 150 |
+
```python
|
| 151 |
+
def generate_latent_points(latent_dim, n)
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
generate points in latent space as input for the generator
|
| 155 |
+
|
| 156 |
+
<a id="utils.ndgan.DCGAN.define_gan"></a>
|
| 157 |
+
|
| 158 |
+
#### define\_gan
|
| 159 |
+
|
| 160 |
+
```python
|
| 161 |
+
def define_gan(generator, discriminator)
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
define the combined generator and discriminator model
|
| 165 |
+
|
| 166 |
+
<a id="utils.ndgan.DCGAN.summarize_performance"></a>
|
| 167 |
+
|
| 168 |
+
#### summarize\_performance
|
| 169 |
+
|
| 170 |
+
```python
|
| 171 |
+
def summarize_performance(epoch, generator, discriminator, latent_dim, n=200)
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
evaluate the discriminator and plot real and fake samples
|
| 175 |
+
|
| 176 |
+
<a id="utils.ndgan.DCGAN.train_gan"></a>
|
| 177 |
+
|
| 178 |
+
#### train\_gan
|
| 179 |
+
|
| 180 |
+
```python
|
| 181 |
+
def train_gan(g_model,
|
| 182 |
+
d_model,
|
| 183 |
+
gan_model,
|
| 184 |
+
latent_dim,
|
| 185 |
+
num_epochs=2500,
|
| 186 |
+
num_eval=2500,
|
| 187 |
+
batch_size=2)
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
function to train gan model
|
| 191 |
+
|
| 192 |
+
<a id="utils.data_augmentation"></a>
|
| 193 |
+
|
| 194 |
+
## utils.data\_augmentation
|
| 195 |
+
|
| 196 |
+
<a id="utils.data_augmentation.dataset"></a>
|
| 197 |
+
|
| 198 |
+
## dataset Objects
|
| 199 |
+
|
| 200 |
+
```python
|
| 201 |
+
class dataset()
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
Creates dataset from input source
|
| 205 |
+
|
| 206 |
+
<a id="utils.data_augmentation.dataset.__init__"></a>
|
| 207 |
+
|
| 208 |
+
#### \_\_init\_\_
|
| 209 |
+
|
| 210 |
+
```python
|
| 211 |
+
def __init__(number_samples: int,
|
| 212 |
+
name: str,
|
| 213 |
+
source: str,
|
| 214 |
+
boundary_conditions: list = None)
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
_summary_
|
| 218 |
+
|
| 219 |
+
**Arguments**:
|
| 220 |
+
|
| 221 |
+
- `number_samples` _int_ - _description_
|
| 222 |
+
- `name` _str_ - _description_
|
| 223 |
+
- `source` _str_ - _description_
|
| 224 |
+
- `boundary_conditions` _list_ - y1,y2,x1,x2
|
| 225 |
+
|
| 226 |
+
<a id="nets"></a>
|
| 227 |
+
|
| 228 |
+
# :orange[nets]
|
| 229 |
+
|
| 230 |
+
<a id="nets.envs"></a>
|
| 231 |
+
|
| 232 |
+
## nets.envs
|
| 233 |
+
|
| 234 |
+
<a id="nets.envs.SCI"></a>
|
| 235 |
+
|
| 236 |
+
### SCI Objects
|
| 237 |
+
|
| 238 |
+
```python
|
| 239 |
+
class SCI()
|
| 240 |
+
```
|
| 241 |
+
|
| 242 |
+
<a id="nets.envs.SCI.data_flow"></a>
|
| 243 |
+
|
| 244 |
+
#### data\_flow
|
| 245 |
+
|
| 246 |
+
```python
|
| 247 |
+
def data_flow(columns_idx: tuple = (1, 3, 3, 5),
|
| 248 |
+
idx: tuple = None,
|
| 249 |
+
split_idx: int = 800) -> torch.utils.data.DataLoader
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
Data prep pipeline
|
| 253 |
+
|
| 254 |
+
**Arguments**:
|
| 255 |
+
|
| 256 |
+
- `columns_idx` _tuple, optional_ - Columns to be selected (sliced 1:2 3:4) for feature fitting. Defaults to (1,3,3,5).
|
| 257 |
+
- `idx` _tuple, optional_ - 2|3 indexes to be selected for feature fitting. Defaults to None. Use either idx or columns_idx (for F:R->R idx, for F:R->R2 columns_idx)
|
| 258 |
+
split_idx (int) : Index to split for training
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
**Returns**:
|
| 262 |
+
|
| 263 |
+
- `torch.utils.data.DataLoader` - Torch native dataloader
|
| 264 |
+
|
| 265 |
+
<a id="nets.envs.SCI.init_seed"></a>
|
| 266 |
+
|
| 267 |
+
#### init\_seed
|
| 268 |
+
|
| 269 |
+
```python
|
| 270 |
+
def init_seed(seed)
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
Initializes seed for torch optional()
|
| 274 |
+
|
| 275 |
+
<a id="nets.envs.SCI.compile"></a>
|
| 276 |
+
|
| 277 |
+
#### compile
|
| 278 |
+
|
| 279 |
+
```python
|
| 280 |
+
def compile(columns: tuple = None,
|
| 281 |
+
idx: tuple = None,
|
| 282 |
+
optim: torch.optim = torch.optim.AdamW,
|
| 283 |
+
loss: nn = nn.L1Loss,
|
| 284 |
+
model: nn.Module = dmodel,
|
| 285 |
+
custom: bool = False) -> None
|
| 286 |
+
```
|
| 287 |
+
|
| 288 |
+
Builds model, loss, optimizer. Has defaults
|
| 289 |
+
|
| 290 |
+
**Arguments**:
|
| 291 |
+
|
| 292 |
+
- `columns` _tuple, optional_ - Columns to be selected for feature fitting. Defaults to (1,3,3,5).
|
| 293 |
+
optim - torch Optimizer
|
| 294 |
+
loss - torch Loss function (nn)
|
| 295 |
+
|
| 296 |
+
<a id="nets.envs.SCI.train"></a>
|
| 297 |
+
|
| 298 |
+
#### train
|
| 299 |
+
|
| 300 |
+
```python
|
| 301 |
+
def train(epochs: int = 10) -> None
|
| 302 |
+
```
|
| 303 |
+
|
| 304 |
+
Train model
|
| 305 |
+
If sklearn instance uses .fit()
|
| 306 |
+
|
| 307 |
+
<a id="nets.envs.SCI.inference"></a>
|
| 308 |
+
|
| 309 |
+
#### inference
|
| 310 |
+
|
| 311 |
+
```python
|
| 312 |
+
def inference(X: tensor, model_name: str = None) -> np.ndarray
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
Inference of (pre-)trained model
|
| 316 |
+
|
| 317 |
+
**Arguments**:
|
| 318 |
+
|
| 319 |
+
- `X` _tensor_ - your data in domain of train
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
**Returns**:
|
| 323 |
+
|
| 324 |
+
- `np.ndarray` - predictions
|
| 325 |
+
|
| 326 |
+
<a id="nets.envs.RCI"></a>
|
| 327 |
+
|
| 328 |
+
### RCI Objects
|
| 329 |
+
|
| 330 |
+
```python
|
| 331 |
+
class RCI(SCI)
|
| 332 |
+
```
|
| 333 |
+
|
| 334 |
+
<a id="nets.envs.RCI.data_flow"></a>
|
| 335 |
+
|
| 336 |
+
#### data\_flow
|
| 337 |
+
|
| 338 |
+
```python
|
| 339 |
+
def data_flow(columns_idx: tuple = (1, 3, 3, 5),
|
| 340 |
+
idx: tuple = None,
|
| 341 |
+
split_idx: int = 800) -> torch.utils.data.DataLoader
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
Data prep pipeline
|
| 345 |
+
|
| 346 |
+
**Arguments**:
|
| 347 |
+
|
| 348 |
+
- `columns_idx` _tuple, optional_ - Columns to be selected (sliced 1:2 3:4) for feature fitting. Defaults to (1,3,3,5).
|
| 349 |
+
- `idx` _tuple, optional_ - 2|3 indexes to be selected for feature fitting. Defaults to None. Use either idx or columns_idx (for F:R->R idx, for F:R->R2 columns_idx)
|
| 350 |
+
split_idx (int) : Index to split for training
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
**Returns**:
|
| 354 |
+
|
| 355 |
+
- `torch.utils.data.DataLoader` - Torch native dataloader
|
| 356 |
+
|
| 357 |
+
<a id="nets.envs.RCI.compile"></a>
|
| 358 |
+
|
| 359 |
+
#### compile
|
| 360 |
+
|
| 361 |
+
```python
|
| 362 |
+
def compile(columns: tuple = None,
|
| 363 |
+
idx: tuple = (3, 1),
|
| 364 |
+
optim: torch.optim = torch.optim.AdamW,
|
| 365 |
+
loss: nn = nn.L1Loss,
|
| 366 |
+
model: nn.Module = PINNd_p,
|
| 367 |
+
lr: float = 0.001) -> None
|
| 368 |
+
```
|
| 369 |
+
|
| 370 |
+
Builds model, loss, optimizer. Has defaults
|
| 371 |
+
|
| 372 |
+
**Arguments**:
|
| 373 |
+
|
| 374 |
+
- `columns` _tuple, optional_ - Columns to be selected for feature fitting. Defaults to None.
|
| 375 |
+
- `idx` _tuple, optional_ - indexes to be selected Default (3,1)
|
| 376 |
+
optim - torch Optimizer
|
| 377 |
+
loss - torch Loss function (nn)
|
| 378 |
+
|
| 379 |
+
<a id="nets.dense"></a>
|
| 380 |
+
|
| 381 |
+
## nets.dense
|
| 382 |
+
|
| 383 |
+
<a id="nets.dense.Net"></a>
|
| 384 |
+
|
| 385 |
+
### Net Objects
|
| 386 |
+
|
| 387 |
+
```python
|
| 388 |
+
class Net(nn.Module)
|
| 389 |
+
```
|
| 390 |
+
|
| 391 |
+
4 layer model, different activations and neurons count on layer
|
| 392 |
+
|
| 393 |
+
<a id="nets.dense.Net.__init__"></a>
|
| 394 |
+
|
| 395 |
+
#### \_\_init\_\_
|
| 396 |
+
|
| 397 |
+
```python
|
| 398 |
+
def __init__(input_dim: int = 2, hidden_dim: int = 200)
|
| 399 |
+
```
|
| 400 |
+
|
| 401 |
+
Init
|
| 402 |
+
|
| 403 |
+
**Arguments**:
|
| 404 |
+
|
| 405 |
+
- `input_dim` _int, optional_ - Defaults to 2.
|
| 406 |
+
- `hidden_dim` _int, optional_ - Defaults to 200.
|
| 407 |
+
|
| 408 |
+
<a id="nets.design"></a>
|
| 409 |
+
|
| 410 |
+
## nets.design
|
| 411 |
+
|
| 412 |
+
<a id="nets.design.B_field_norm"></a>
|
| 413 |
+
|
| 414 |
+
#### B\_field\_norm
|
| 415 |
+
|
| 416 |
+
```python
|
| 417 |
+
def B_field_norm(Bmax, L, k=16, plot=True)
|
| 418 |
+
```
|
| 419 |
+
|
| 420 |
+
Returns vec B_z
|
| 421 |
+
|
| 422 |
+
**Arguments**:
|
| 423 |
+
|
| 424 |
+
- `Bmax` _any_ - maximum B in thruster
|
| 425 |
+
k - magnetic field profile number
|
| 426 |
+
|
| 427 |
+
<a id="nets.deep_dense"></a>
|
| 428 |
+
|
| 429 |
+
## nets.deep\_dense
|
| 430 |
+
|
| 431 |
+
<a id="nets.deep_dense.dmodel"></a>
|
| 432 |
+
|
| 433 |
+
### dmodel Objects
|
| 434 |
+
|
| 435 |
+
```python
|
| 436 |
+
class dmodel(nn.Module)
|
| 437 |
+
```
|
| 438 |
+
|
| 439 |
+
4 layers Torch model. Relu activations, hidden layers are same size.
|
| 440 |
+
|
| 441 |
+
<a id="nets.deep_dense.dmodel.__init__"></a>
|
| 442 |
+
|
| 443 |
+
#### \_\_init\_\_
|
| 444 |
+
|
| 445 |
+
```python
|
| 446 |
+
def __init__(in_features=1, hidden_features=200, out_features=1)
|
| 447 |
+
```
|
| 448 |
+
|
| 449 |
+
Init
|
| 450 |
+
|
| 451 |
+
**Arguments**:
|
| 452 |
+
|
| 453 |
+
- `in_features` _int, optional_ - Input features. Defaults to 1.
|
| 454 |
+
- `hidden_features` _int, optional_ - Hidden dims. Defaults to 200.
|
| 455 |
+
- `out_features` _int, optional_ - Output dims. Defaults to 1.
|
| 456 |
+
|
nets/__init__.py
ADDED
|
File without changes
|
nets/__pycache__/HET_dense.cpython-310.pyc
ADDED
|
Binary file (9.88 kB). View file
|
|
|
nets/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (140 Bytes). View file
|
|
|
nets/__pycache__/deep_dense.cpython-310.pyc
ADDED
|
Binary file (1.3 kB). View file
|
|
|
nets/__pycache__/dense.cpython-310.pyc
ADDED
|
Binary file (1.2 kB). View file
|
|
|
nets/__pycache__/design.cpython-310.pyc
ADDED
|
Binary file (1.55 kB). View file
|
|
|
nets/__pycache__/envs.cpython-310.pyc
ADDED
|
Binary file (19.9 kB). View file
|
|
|
nets/deep_dense.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
from torch.functional import F
|
| 3 |
+
|
| 4 |
+
class dmodel(nn.Module):
|
| 5 |
+
"""4 layers Torch model. Relu activations, hidden layers are same size.
|
| 6 |
+
|
| 7 |
+
"""
|
| 8 |
+
def __init__(self, in_features=1, hidden_features=200, out_features=1):
|
| 9 |
+
"""Init
|
| 10 |
+
|
| 11 |
+
Args:
|
| 12 |
+
in_features (int, optional): Input features. Defaults to 1.
|
| 13 |
+
hidden_features (int, optional): Hidden dims. Defaults to 200.
|
| 14 |
+
out_features (int, optional): Output dims. Defaults to 1.
|
| 15 |
+
"""
|
| 16 |
+
super(dmodel, self).__init__()
|
| 17 |
+
|
| 18 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 19 |
+
self.fc2 = nn.Linear(hidden_features, hidden_features)
|
| 20 |
+
self.fc3 = nn.Linear(hidden_features, hidden_features)
|
| 21 |
+
self.fc4 = nn.Linear(hidden_features, out_features)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def forward(self, x):
|
| 25 |
+
x = self.fc1(x)
|
| 26 |
+
x = F.relu(x) # ReLU activation
|
| 27 |
+
x = self.fc2(x)
|
| 28 |
+
x = F.relu(x) # ReLU activation
|
| 29 |
+
x = self.fc3(x)
|
| 30 |
+
x = F.relu(x) # ReLU activation
|
| 31 |
+
x = self.fc4(x)
|
| 32 |
+
return x
|
nets/dense.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
|
| 3 |
+
class Net(nn.Module):
|
| 4 |
+
"""4 layer model, different activations and neurons count on layer
|
| 5 |
+
|
| 6 |
+
"""
|
| 7 |
+
def __init__(self,input_dim:int=2,hidden_dim:int=200):
|
| 8 |
+
"""Init
|
| 9 |
+
|
| 10 |
+
Args:
|
| 11 |
+
input_dim (int, optional): Defaults to 2.
|
| 12 |
+
hidden_dim (int, optional): Defaults to 200.
|
| 13 |
+
"""
|
| 14 |
+
super(Net,self).__init__()
|
| 15 |
+
self.input = nn.Linear(input_dim,40)
|
| 16 |
+
self.act1 = nn.Tanh()
|
| 17 |
+
self.layer = nn.Linear(40,80)
|
| 18 |
+
self.act2 = nn.ReLU()
|
| 19 |
+
self.layer1 = nn.Linear(80,hidden_dim)
|
| 20 |
+
self.act3 = nn.ReLU()
|
| 21 |
+
self.layer2 = nn.Linear(hidden_dim,1)
|
| 22 |
+
|
| 23 |
+
def forward(self, x):
|
| 24 |
+
x = self.act2(self.layer(self.act1(self.input(x))))
|
| 25 |
+
x = self.act3(self.layer1(x))
|
| 26 |
+
x = self.layer2(x)
|
| 27 |
+
return x
|
nets/design.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import seaborn as sns
|
| 3 |
+
import pandas as pd
|
| 4 |
+
|
| 5 |
+
def B_field_norm(Bmax:float,L:float,k:int=16,plot=True) -> np.array:
|
| 6 |
+
""" Returns vec B_z for MS config
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
Bmax (any): maximum B in thruster
|
| 10 |
+
L - channel length
|
| 11 |
+
k - magnetic field profile number
|
| 12 |
+
"""
|
| 13 |
+
z = np.linspace(0,L*1.4,200)
|
| 14 |
+
B = Bmax * np.exp(-k * (z/(1.2*L) - 1)**2)
|
| 15 |
+
if plot:
|
| 16 |
+
sns.lineplot(x=z,y=B)
|
| 17 |
+
return z,B
|
| 18 |
+
|
| 19 |
+
def PUdesign(P:float,U:float) -> pd.DataFrame:
|
| 20 |
+
"""Computes design via numerical model, uses fits from PINNs
|
| 21 |
+
|
| 22 |
+
Args:
|
| 23 |
+
P (float): _description_
|
| 24 |
+
U (float): _description_
|
| 25 |
+
|
| 26 |
+
Returns:
|
| 27 |
+
_type_: _description_
|
| 28 |
+
"""
|
| 29 |
+
d = np.sqrt(P/(635*U))
|
| 30 |
+
h = 0.245*d
|
| 31 |
+
m_a = 0.0025*h*d
|
| 32 |
+
T = 890 * m_a * np.sqrt(U)
|
| 33 |
+
j = P/(np.pi*d*h)
|
| 34 |
+
Isp = T/(m_a*9.81)
|
| 35 |
+
nu_t = T*Isp*9.81/(2*P)
|
| 36 |
+
df = pd.DataFrame([[d,h,m_a,T,j,nu_t,Isp]],columns=['d','h','m_a','T','j','nu_t','Isp'])
|
| 37 |
+
g = sns.barplot(df,facecolor='gray')
|
| 38 |
+
g.set_yscale("log")
|
| 39 |
+
return df
|
| 40 |
+
|
| 41 |
+
def cathode_erosion():
|
| 42 |
+
pass
|
nets/envs.py
ADDED
|
@@ -0,0 +1,491 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils.dataset_loader import get_dataset
|
| 2 |
+
from nets.dense import Net
|
| 3 |
+
from nets.deep_dense import dmodel
|
| 4 |
+
from PINN.pinns import *
|
| 5 |
+
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import seaborn as sns
|
| 8 |
+
import torch
|
| 9 |
+
import os
|
| 10 |
+
import numpy as np
|
| 11 |
+
from torch import nn, tensor
|
| 12 |
+
import pandas as pd
|
| 13 |
+
import plotly.express as px
|
| 14 |
+
from sklearn.linear_model import SGDRegressor
|
| 15 |
+
from sklearn.feature_selection import SelectFromModel
|
| 16 |
+
|
| 17 |
+
class SCI(): #Scaled Computing Interface
|
| 18 |
+
""" Scaled computing interface.
|
| 19 |
+
Args:
|
| 20 |
+
hidden_dim (int, optional): Max demension of hidden linear layer. Defaults to 200. Should be >80 in not 1d case
|
| 21 |
+
dropout (bool, optional): LEGACY, don't use. Defaults to True.
|
| 22 |
+
epochs (int, optional): Optionally specify epochs here, but better in train. Defaults to 10.
|
| 23 |
+
dataset (str, optional): dataset to be selected from ./data. Defaults to 'test.pkl'. If name not exists, code will generate new dataset with upcoming parameters.
|
| 24 |
+
sample_size (int, optional): Samples to be generated (note: BEFORE applying boundary conditions). Defaults to 1000.
|
| 25 |
+
source (str, optional): Source from which data will be generated. Better to not change. Defaults to 'dataset.csv'.
|
| 26 |
+
boundary_conditions (list, optional): If sepcified, whole dataset will be cut rectangulary. Input list is [ymin,ymax,xmin,xmax] type. Defaults to None.
|
| 27 |
+
"""
|
| 28 |
+
def __init__(self, hidden_dim:int = 200, dropout:bool = True, epochs:int = 10, dataset:str = 'test.pkl',sample_size:int=1000,source:str='dataset.csv',boundary_conditions:list=None):
|
| 29 |
+
"""Init
|
| 30 |
+
Args:
|
| 31 |
+
hidden_dim (int, optional): Max demension of hidden linear layer. Defaults to 200. Should be >80 in not 1d case
|
| 32 |
+
dropout (bool, optional): LEGACY, don't use. Defaults to True.
|
| 33 |
+
epochs (int, optional): Optionally specify epochs here, but better in train. Defaults to 10.
|
| 34 |
+
dataset (str, optional): dataset to be selected from ./data. Defaults to 'test.pkl'. If name not exists, code will generate new dataset with upcoming parameters.
|
| 35 |
+
sample_size (int, optional): Samples to be generated (note: BEFORE applying boundary conditions). Defaults to 1000.
|
| 36 |
+
source (str, optional): Source from which data will be generated. Better to not change. Defaults to 'dataset.csv'.
|
| 37 |
+
boundary_conditions (list, optional): If sepcified, whole dataset will be cut rectangulary. Input list is [ymin,ymax,xmin,xmax] type. Defaults to None.
|
| 38 |
+
"""
|
| 39 |
+
self.type:str = 'legacy'
|
| 40 |
+
self.seed:int = 449
|
| 41 |
+
self.dim = hidden_dim
|
| 42 |
+
self.dropout = dropout
|
| 43 |
+
self.df = get_dataset(sample_size=sample_size,source=source,name=dataset,boundary_conditions=boundary_conditions)
|
| 44 |
+
self.epochs = epochs
|
| 45 |
+
self.len_idx = 0
|
| 46 |
+
self.input_dim_for_check = 0
|
| 47 |
+
|
| 48 |
+
def feature_gen(self, base:bool=True, fname:str=None,index:int=None,func=None) -> None:
|
| 49 |
+
""" Generate new features. If base true, generates most obvious ones. You can customize this by adding
|
| 50 |
+
new feature as name of column - fname, index of parent column, and lambda function which needs to be applied elementwise.
|
| 51 |
+
Args:
|
| 52 |
+
base (bool, optional): Defaults to True.
|
| 53 |
+
fname (str, optional): Name of new column. Defaults to None.
|
| 54 |
+
index (int, optional): Index of parent column. Defaults to None.
|
| 55 |
+
func (_type_, optional): lambda function. Defaults to None.
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
if base:
|
| 59 |
+
self.df['P_sqrt'] = self.df.iloc[:,1].apply(lambda x: x ** 0.5)
|
| 60 |
+
self.df['j'] = self.df.iloc[:,1]/(self.df.iloc[:,3]*self.df.iloc[:,4])
|
| 61 |
+
self.df['B'] = self.df.iloc[:,-1].apply(lambda x: x ** 2).apply(lambda x:1 if x>1 else x)
|
| 62 |
+
self.df['nu_t'] = self.df.iloc[:,7]**2/(2*self.df.iloc[:,6]*self.df.P)
|
| 63 |
+
|
| 64 |
+
if fname and index and func:
|
| 65 |
+
self.df[fname] = self.df.iloc[:,index].apply(func)
|
| 66 |
+
|
| 67 |
+
def feature_importance(self,X:pd.DataFrame,Y:pd.Series,verbose:int=1):
|
| 68 |
+
""" Gets feature importance by SGD regression and score selection. Default threshold is 1.25*mean
|
| 69 |
+
input X as self.df.iloc[:,(columns of choice)]
|
| 70 |
+
Y as self.df.iloc[:,(column of choice)]
|
| 71 |
+
Args:
|
| 72 |
+
X (pd.DataFrame): Builtin DataFrame
|
| 73 |
+
Y (pd.Series): Builtin Series
|
| 74 |
+
verbose (int, optional): either to or to not print actual report. Defaults to 1.
|
| 75 |
+
Returns:
|
| 76 |
+
Report (str)
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
mod = SGDRegressor()
|
| 80 |
+
|
| 81 |
+
selector = SelectFromModel(mod,threshold='1.25*mean')
|
| 82 |
+
selector.fit(np.array(X),np.array(Y))
|
| 83 |
+
|
| 84 |
+
if verbose:
|
| 85 |
+
print(f'\n Report of feature importance: {dict(zip(X.columns,selector.estimator_.coef_))}')
|
| 86 |
+
for i in range(len(selector.get_support())):
|
| 87 |
+
if selector.get_support()[i]:
|
| 88 |
+
print(f'-rank 1 PASSED:',X.columns[i])
|
| 89 |
+
else:
|
| 90 |
+
print(f'-rank 0 REJECT:',X.columns[i])
|
| 91 |
+
return f'\n Report of feature importance: {dict(zip(X.columns,selector.estimator_.coef_))}'
|
| 92 |
+
|
| 93 |
+
def data_flow(self,columns_idx:tuple = (1,3,3,5), idx:tuple=None, split_idx:int = 800) -> torch.utils.data.DataLoader:
|
| 94 |
+
""" Data prep pipeline
|
| 95 |
+
It is called automatically, don't call it in your code.
|
| 96 |
+
Args:
|
| 97 |
+
columns_idx (tuple, optional): Columns to be selected (sliced 1:2 3:4) for feature fitting. Defaults to (1,3,3,5).
|
| 98 |
+
idx (tuple, optional): 2|3 indexes to be selected for feature fitting. Defaults to None. Use either idx or columns_idx (for F:R->R idx, for F:R->R2 columns_idx)
|
| 99 |
+
split_idx (int) : Index to split for training
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
torch.utils.data.DataLoader: Torch native dataloader
|
| 103 |
+
"""
|
| 104 |
+
batch_size=2
|
| 105 |
+
|
| 106 |
+
self.split_idx=split_idx
|
| 107 |
+
|
| 108 |
+
if idx!=None:
|
| 109 |
+
self.len_idx = len(idx)
|
| 110 |
+
if len(idx)==2:
|
| 111 |
+
self.X = tensor(self.df.iloc[:,idx[0]].values[:split_idx]).float()
|
| 112 |
+
self.Y = tensor(self.df.iloc[:,idx[1]].values[:split_idx]).float()
|
| 113 |
+
batch_size = 1
|
| 114 |
+
else:
|
| 115 |
+
self.X = tensor(self.df.iloc[:,[*idx[:-1]]].values[:split_idx,:]).float()
|
| 116 |
+
self.Y = tensor(self.df.iloc[:,idx[2]].values[:split_idx]).float()
|
| 117 |
+
else:
|
| 118 |
+
self.X = tensor(self.df.iloc[:,columns_idx[0]:columns_idx[1]].values[:split_idx,:]).float()
|
| 119 |
+
self.Y = tensor(self.df.iloc[:,columns_idx[2]:columns_idx[3]].values[:split_idx]).float()
|
| 120 |
+
|
| 121 |
+
print('Shapes for debug: (X,Y)',self.X.shape, self.Y.shape)
|
| 122 |
+
train_data = torch.utils.data.TensorDataset(self.X, self.Y)
|
| 123 |
+
Xtrain = torch.utils.data.DataLoader(train_data,batch_size=batch_size)
|
| 124 |
+
self.input_dim = self.X.size(-1)
|
| 125 |
+
self.indexes = idx if idx else columns_idx
|
| 126 |
+
self.column_names = [self.df.columns[i] for i in self.indexes]
|
| 127 |
+
return Xtrain
|
| 128 |
+
|
| 129 |
+
def init_seed(self,seed):
|
| 130 |
+
""" Initializes seed for torch optional()
|
| 131 |
+
"""
|
| 132 |
+
|
| 133 |
+
torch.manual_seed(seed)
|
| 134 |
+
|
| 135 |
+
def train_epoch(self,X, model, loss_function, optim):
|
| 136 |
+
for i,data in enumerate(X):
|
| 137 |
+
Y_pred = model(data[0])
|
| 138 |
+
loss = loss_function(Y_pred, data[1])
|
| 139 |
+
|
| 140 |
+
# mean_abs_percentage_error = MeanAbsolutePercentageError()
|
| 141 |
+
# ape = mean_abs_percentage_error(Y_pred, data[1])
|
| 142 |
+
|
| 143 |
+
loss.backward()
|
| 144 |
+
optim.step()
|
| 145 |
+
optim.zero_grad()
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
ape_norm = abs(np.mean((Y_pred.detach().numpy()-data[1].detach().numpy())/(data[1].detach().numpy()+0.1)))
|
| 149 |
+
if (i+1)%200==0:
|
| 150 |
+
print(f'Iter {i+1} APE =',ape_norm)
|
| 151 |
+
self.loss_history.append(loss.data.item())
|
| 152 |
+
self.ape_history.append(None if ape_norm >1 else ape_norm)
|
| 153 |
+
|
| 154 |
+
def compile(self,columns:tuple=None,idx:tuple=None, optim:torch.optim = torch.optim.AdamW,loss:nn=nn.L1Loss, model:nn.Module = dmodel, custom:bool=False, lr:float=0.0001) -> None:
|
| 155 |
+
""" Builds model, loss, optimizer. Has defaults
|
| 156 |
+
Args:
|
| 157 |
+
columns (tuple, optional): Columns to be selected for feature fitting. Defaults to (1,3,3,5).
|
| 158 |
+
optim - torch Optimizer. Default AdamW
|
| 159 |
+
loss - torch Loss function (nn). Defaults to L1Loss
|
| 160 |
+
"""
|
| 161 |
+
|
| 162 |
+
self.columns = columns
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
if not(columns):
|
| 166 |
+
self.len_idx = 0
|
| 167 |
+
else:
|
| 168 |
+
self.len_idx = len(columns)
|
| 169 |
+
|
| 170 |
+
if not(self.columns) and not(idx):
|
| 171 |
+
self.Xtrain = self.data_flow()
|
| 172 |
+
elif not(idx):
|
| 173 |
+
self.Xtrain = self.data_flow(columns_idx=self.columns)
|
| 174 |
+
else:
|
| 175 |
+
self.Xtrain = self.data_flow(idx=idx)
|
| 176 |
+
|
| 177 |
+
if custom:
|
| 178 |
+
self.model = model()
|
| 179 |
+
self.loss_function = loss()
|
| 180 |
+
self.optim = optim(self.model.parameters(), lr=lr)
|
| 181 |
+
if self.len_idx == 2:
|
| 182 |
+
self.input_dim_for_check = 1
|
| 183 |
+
else:
|
| 184 |
+
if self.len_idx == 2:
|
| 185 |
+
self.model = model(in_features=1,hidden_features=self.dim).float()
|
| 186 |
+
self.input_dim_for_check = 1
|
| 187 |
+
if self.len_idx == 3:
|
| 188 |
+
self.model = Net(input_dim=2,hidden_dim=self.dim).float()
|
| 189 |
+
if (self.len_idx != 2 or 3) or self.columns:
|
| 190 |
+
self.model = Net(input_dim=self.input_dim,hidden_dim=self.dim).float()
|
| 191 |
+
|
| 192 |
+
self.optim = optim(self.model.parameters(), lr=lr)
|
| 193 |
+
self.loss_function = loss()
|
| 194 |
+
|
| 195 |
+
if self.input_dim_for_check:
|
| 196 |
+
self.X = self.X.reshape(-1,1)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def train(self,epochs:int=10) -> None:
|
| 201 |
+
""" Train model
|
| 202 |
+
If sklearn instance uses .fit()
|
| 203 |
+
|
| 204 |
+
epochs - optional
|
| 205 |
+
"""
|
| 206 |
+
if 'sklearn' in str(self.model.__class__):
|
| 207 |
+
self.model.fit(np.array(self.X),np.array(self.Y))
|
| 208 |
+
plt.scatter(self.X,self.model.predict(self.X))
|
| 209 |
+
plt.scatter(self.X,self.Y)
|
| 210 |
+
plt.xlabel('Xreal')
|
| 211 |
+
plt.ylabel('Ypred/Yreal')
|
| 212 |
+
plt.show()
|
| 213 |
+
return print('Sklearn model fitted successfully')
|
| 214 |
+
else:
|
| 215 |
+
self.model.train()
|
| 216 |
+
|
| 217 |
+
self.loss_history = []
|
| 218 |
+
self.ape_history = []
|
| 219 |
+
|
| 220 |
+
self.epochs = epochs
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
for j in range(self.epochs):
|
| 224 |
+
self.train_epoch(self.Xtrain,self.model,self.loss_function,self.optim)
|
| 225 |
+
|
| 226 |
+
plt.plot(self.loss_history,label='loss_history')
|
| 227 |
+
plt.legend()
|
| 228 |
+
|
| 229 |
+
def save(self,name:str='model.pt') -> None:
|
| 230 |
+
torch.save(self.model,name)
|
| 231 |
+
|
| 232 |
+
def onnx_export(self,path:str='./models/model.onnx'):
|
| 233 |
+
torch.onnx.export(self.model,self.X,path)
|
| 234 |
+
|
| 235 |
+
def jit_export(self,path:str='./models/model.pt'):
|
| 236 |
+
"""Exports properly defined model to jit
|
| 237 |
+
Args:
|
| 238 |
+
path (str, optional): path to models. Defaults to './models/model.pt'.
|
| 239 |
+
"""
|
| 240 |
+
torch.jit.save(self.model,path)
|
| 241 |
+
|
| 242 |
+
def inference(self,X:tensor, model_name:str=None) -> np.ndarray:
|
| 243 |
+
""" Inference of (pre-)trained model
|
| 244 |
+
Args:
|
| 245 |
+
X (tensor): your data in domain of train
|
| 246 |
+
Returns:
|
| 247 |
+
np.ndarray: predictions
|
| 248 |
+
"""
|
| 249 |
+
if model_name is None:
|
| 250 |
+
self.model.eval()
|
| 251 |
+
|
| 252 |
+
if model_name in os.listdir('./models'):
|
| 253 |
+
model = torch.load(f'./models/{model_name}')
|
| 254 |
+
model.eval()
|
| 255 |
+
return model(X).detach().numpy()
|
| 256 |
+
|
| 257 |
+
return self.model(X).detach().numpy()
|
| 258 |
+
|
| 259 |
+
def plot(self):
|
| 260 |
+
""" Automatic 2d plot
|
| 261 |
+
"""
|
| 262 |
+
self.model.eval()
|
| 263 |
+
print(self.Y.shape,self.model(self.X).detach().numpy().shape,self.X.shape)
|
| 264 |
+
if self.X.shape[-1] != self.model(self.X).detach().numpy().shape[-1]:
|
| 265 |
+
print('Size mismatch, try 3d plot, plotting by first dim of largest tensor')
|
| 266 |
+
if len(self.X.shape)==1:
|
| 267 |
+
X = self.X
|
| 268 |
+
else: X = self.X[:,0]
|
| 269 |
+
plt.scatter(X,self.model(self.X).detach().numpy(),label='predicted',s=2)
|
| 270 |
+
if len(self.Y.shape)!=1:
|
| 271 |
+
plt.scatter(X,self.Y[:,1],s=1,label='real')
|
| 272 |
+
else:
|
| 273 |
+
plt.scatter(X,self.Y,s=1,label='real')
|
| 274 |
+
plt.xlabel(rf'${self.column_names[0]}$')
|
| 275 |
+
plt.ylabel(rf'${self.column_names[1]}$')
|
| 276 |
+
plt.legend()
|
| 277 |
+
else:
|
| 278 |
+
plt.scatter(self.X,self.model(self.X).detach().numpy(),s=2,label='predicted')
|
| 279 |
+
plt.scatter(self.X,self.Y,s=1,label='real')
|
| 280 |
+
plt.xlabel(r'$X$')
|
| 281 |
+
plt.ylabel(r'$Y$')
|
| 282 |
+
plt.legend()
|
| 283 |
+
|
| 284 |
+
def plot3d(self,colX=0,colY=1):
|
| 285 |
+
""" Plot of inputs and predicted data in mesh format
|
| 286 |
+
Returns:
|
| 287 |
+
plotly plot
|
| 288 |
+
"""
|
| 289 |
+
X = self.X
|
| 290 |
+
self.model.eval()
|
| 291 |
+
x = X[:,colX].numpy().ravel()
|
| 292 |
+
y = X[:,colY].numpy().ravel()
|
| 293 |
+
z = self.model(X).detach().numpy().ravel()
|
| 294 |
+
surf = px.scatter_3d(x=x, y=y,z=self.df.iloc[:,self.indexes[-1]].values[:self.split_idx],opacity=0.3,
|
| 295 |
+
labels={'x':f'{self.column_names[colX]}',
|
| 296 |
+
'y':f'{self.column_names[colY]}',
|
| 297 |
+
'z':f'{self.column_names[-1]}'
|
| 298 |
+
},title='Mesh prediction plot'
|
| 299 |
+
)
|
| 300 |
+
# fig.colorbar(surf, shrink=0.5, aspect=5)
|
| 301 |
+
surf.update_traces(marker_size=3)
|
| 302 |
+
surf.update_layout(plot_bgcolor='#888888')
|
| 303 |
+
surf.add_mesh3d(x=x, y=y, z=z, opacity=0.7,colorscale='sunsetdark',intensity=z,
|
| 304 |
+
)
|
| 305 |
+
# surf.show()
|
| 306 |
+
|
| 307 |
+
return surf
|
| 308 |
+
def performance(self,c=0.4) -> dict:
|
| 309 |
+
""" Automatic APE based performance if applicable, else returns nan
|
| 310 |
+
Args:
|
| 311 |
+
c (float, optional): ZDE mitigation constant. Defaults to 0.4.
|
| 312 |
+
Returns:
|
| 313 |
+
dict: {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 314 |
+
"""
|
| 315 |
+
a=[]
|
| 316 |
+
for i in range(1000):
|
| 317 |
+
a.append(100-abs(np.mean(self.df.iloc[1:24,1:8].values-self.df.iloc[24:,1:8].sample(23).values)/(self.Y.numpy()[1:]+c))*100)
|
| 318 |
+
gen_acc = np.mean(a)
|
| 319 |
+
ape = (100-abs(np.mean(self.model(self.X).detach().numpy()-self.Y.numpy()[1:])*100))
|
| 320 |
+
abs_ape = ape*gen_acc/100
|
| 321 |
+
return {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 322 |
+
|
| 323 |
+
def performance_super(self,c=0.4,real_data_column_index:tuple = (1,8),real_data_samples:int=23, generated_length:int=1000) -> dict:
|
| 324 |
+
"""Performance by custom parameters. APE loss
|
| 325 |
+
Args:
|
| 326 |
+
c (float, optional): ZDE mitigation constant. Defaults to 0.4.
|
| 327 |
+
real_data_column_index (tuple, optional): Defaults to (1,8).
|
| 328 |
+
real_data_samples (int, optional): Defaults to 23.
|
| 329 |
+
generated_length (int, optional): Defaults to 1000.
|
| 330 |
+
Returns:
|
| 331 |
+
dict: {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 332 |
+
"""
|
| 333 |
+
a=[]
|
| 334 |
+
for i in range(1000):
|
| 335 |
+
a.append(100-abs(np.mean(self.df.iloc[1:real_data_samples+1,real_data_column_index[0]:real_data_column_index[1]].values-self.df.iloc[real_data_samples+1:,real_data_column_index[0]:real_data_column_index[1]].sample(real_data_samples).values)/(self.Y.numpy()[1:]+c))*100)
|
| 336 |
+
gen_acc = np.mean(a)
|
| 337 |
+
ape = (100-abs(np.mean(self.model(self.X).detach().numpy()-self.Y.numpy()[1:])*100))
|
| 338 |
+
abs_ape = ape*gen_acc/100
|
| 339 |
+
return {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 340 |
+
|
| 341 |
+
def performance_super(self,c=0.4,real_data_column_index:tuple = (1,8),real_data_samples:int=23, generated_length:int=1000) -> dict:
|
| 342 |
+
a=[]
|
| 343 |
+
for i in range(1000):
|
| 344 |
+
a.append(100-abs(np.mean(self.df.iloc[1:real_data_samples+1,real_data_column_index[0]:real_data_column_index[1]].values-self.df.iloc[real_data_samples+1:,real_data_column_index[0]:real_data_column_index[1]].sample(real_data_samples).values)/(self.Y.numpy()[1:]+c))*100)
|
| 345 |
+
gen_acc = np.mean(a)
|
| 346 |
+
ape = (100-abs(np.mean(self.model(self.X).detach().numpy()-self.Y.numpy()[1:])*100))
|
| 347 |
+
abs_ape = ape*gen_acc/100
|
| 348 |
+
return {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 349 |
+
def performance_super(self,c=0.4,real_data_column_index:tuple = (1,8),real_data_samples:int=23, generated_length:int=1000) -> dict:
|
| 350 |
+
a=[]
|
| 351 |
+
for i in range(1000):
|
| 352 |
+
a.append(100-abs(np.mean(self.df.iloc[1:real_data_samples+1,real_data_column_index[0]:real_data_column_index[1]].values-self.df.iloc[real_data_samples+1:,real_data_column_index[0]:real_data_column_index[1]].sample(real_data_samples).values)/(self.Y.numpy()[1:]+c))*100)
|
| 353 |
+
gen_acc = np.mean(a)
|
| 354 |
+
ape = (100-abs(np.mean(self.model(self.X).detach().numpy()-self.Y.numpy()[1:])*100))
|
| 355 |
+
abs_ape = ape*gen_acc/100
|
| 356 |
+
return {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 357 |
+
|
| 358 |
+
class RCI(SCI): #Real object interface
|
| 359 |
+
""" Real values interface, uses different types of NN, NO scaling.
|
| 360 |
+
Parent:
|
| 361 |
+
SCI()
|
| 362 |
+
"""
|
| 363 |
+
def __init__(self,*args,**kwargs):
|
| 364 |
+
super(RCI,self).__init__()
|
| 365 |
+
|
| 366 |
+
def data_flow(self,columns_idx:tuple = (1,3,3,5), idx:tuple=None, split_idx:int = 800) -> torch.utils.data.DataLoader:
|
| 367 |
+
""" Data prep pipeline
|
| 368 |
+
Args:
|
| 369 |
+
columns_idx (tuple, optional): Columns to be selected (sliced 1:2 3:4) for feature fitting. Defaults to (1,3,3,5).
|
| 370 |
+
idx (tuple, optional): 2|3 indexes to be selected for feature fitting. Defaults to None. Use either idx or columns_idx (for F:R->R idx, for F:R->R2 columns_idx)
|
| 371 |
+
split_idx (int) : Index to split for training
|
| 372 |
+
|
| 373 |
+
Returns:
|
| 374 |
+
torch.utils.data.DataLoader: Torch native dataloader
|
| 375 |
+
"""
|
| 376 |
+
batch_size=2
|
| 377 |
+
|
| 378 |
+
real_scale = pd.read_csv('data/dataset.csv').iloc[17,1:].to_numpy()
|
| 379 |
+
self.df.iloc[:,1:] = self.df.iloc[:,1:] * real_scale
|
| 380 |
+
|
| 381 |
+
self.split_idx=split_idx
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
if idx!=None:
|
| 385 |
+
self.len_idx = len(idx)
|
| 386 |
+
if len(idx)==2:
|
| 387 |
+
self.X = tensor(self.df.iloc[:,idx[0]].values[:split_idx].astype(float)).float()
|
| 388 |
+
self.Y = tensor(self.df.iloc[:,idx[1]].values[:split_idx].astype(float)).float()
|
| 389 |
+
batch_size = 1
|
| 390 |
+
else:
|
| 391 |
+
self.X = tensor(self.df.iloc[:,[idx[0],idx[1]]].values[:split_idx,:].astype(float)).float()
|
| 392 |
+
self.Y = tensor(self.df.iloc[:,idx[2]].values[:split_idx].astype(float)).float()
|
| 393 |
+
else:
|
| 394 |
+
self.X = tensor(self.df.iloc[:,columns_idx[0]:columns_idx[1]].values[:split_idx,:].astype(float)).float()
|
| 395 |
+
self.Y = tensor(self.df.iloc[:,columns_idx[2]:columns_idx[3]].values[:split_idx].astype(float)).float()
|
| 396 |
+
self.Y = self.Y.abs()
|
| 397 |
+
self.X = self.X.abs()
|
| 398 |
+
|
| 399 |
+
print('Shapes for debug: (X,Y)',self.X.shape, self.Y.shape)
|
| 400 |
+
train_data = torch.utils.data.TensorDataset(self.X, self.Y)
|
| 401 |
+
Xtrain = torch.utils.data.DataLoader(train_data,batch_size=batch_size)
|
| 402 |
+
self.input_dim = self.X.size(-1)
|
| 403 |
+
self.indexes = idx if idx else columns_idx
|
| 404 |
+
self.column_names = [ self.df.columns[i] for i in self.indexes ]
|
| 405 |
+
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
return Xtrain
|
| 410 |
+
|
| 411 |
+
def compile(self,columns:tuple=None,idx:tuple=(3,1), optim:torch.optim = torch.optim.AdamW,loss:nn=nn.L1Loss, model:nn.Module = PINNd_p,lr:float=0.001) -> None:
|
| 412 |
+
""" Builds model, loss, optimizer. Has defaults
|
| 413 |
+
Args:
|
| 414 |
+
columns (tuple, optional): Columns to be selected for feature fitting. Defaults to None.
|
| 415 |
+
idx (tuple, optional): indexes to be selected Default (3,1)
|
| 416 |
+
optim - torch Optimizer
|
| 417 |
+
loss - torch Loss function (nn)
|
| 418 |
+
"""
|
| 419 |
+
|
| 420 |
+
self.columns = columns
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
if not(columns):
|
| 424 |
+
self.len_idx = 0
|
| 425 |
+
else:
|
| 426 |
+
self.len_idx = len(columns)
|
| 427 |
+
|
| 428 |
+
if not(self.columns) and not(idx):
|
| 429 |
+
self.Xtrain = self.data_flow()
|
| 430 |
+
elif not(idx):
|
| 431 |
+
self.Xtrain = self.data_flow(columns_idx=self.columns)
|
| 432 |
+
else:
|
| 433 |
+
self.Xtrain = self.data_flow(idx=idx)
|
| 434 |
+
|
| 435 |
+
self.model = model().float()
|
| 436 |
+
self.input_dim_for_check = self.X.size(-1)
|
| 437 |
+
|
| 438 |
+
self.optim = optim(self.model.parameters(), lr=lr)
|
| 439 |
+
self.loss_function = loss()
|
| 440 |
+
|
| 441 |
+
if self.input_dim_for_check == 1:
|
| 442 |
+
self.X = self.X.reshape(-1,1)
|
| 443 |
+
def plot(self):
|
| 444 |
+
""" Plots 2d plot of prediction vs real values
|
| 445 |
+
"""
|
| 446 |
+
self.model.eval()
|
| 447 |
+
if 'PINN' in str(self.model.__class__):
|
| 448 |
+
self.preds=np.array([])
|
| 449 |
+
for i in self.X:
|
| 450 |
+
self.preds = np.append(self.preds,self.model(i).detach().numpy())
|
| 451 |
+
print(self.Y.shape,self.preds.shape,self.X.shape)
|
| 452 |
+
if self.X.shape[-1] != self.preds.shape[-1]:
|
| 453 |
+
print('Size mismatch, try 3d plot, plotting by first dim of largest tensor')
|
| 454 |
+
try: X = self.X[:,0]
|
| 455 |
+
except:
|
| 456 |
+
X = self.X
|
| 457 |
+
pass
|
| 458 |
+
plt.scatter(X,self.preds,label='predicted',s=2)
|
| 459 |
+
if self.Y.shape[-1]!=1:
|
| 460 |
+
sns.scatterplot(x=X,y=self.Y,s=2,label='real')
|
| 461 |
+
else:
|
| 462 |
+
sns.scatterplot(x=X,y=self.Y,s=1,label='real')
|
| 463 |
+
plt.xlabel(rf'${self.column_names[0]}$')
|
| 464 |
+
plt.ylabel(rf'${self.column_names[1]}$')
|
| 465 |
+
plt.legend()
|
| 466 |
+
else:
|
| 467 |
+
sns.scatterplot(x=self.X,y=self.preds,s=2,label='predicted')
|
| 468 |
+
sns.scatterplot(x=self.X,y=self.Y,s=1,label='real')
|
| 469 |
+
plt.xlabel(r'$X$')
|
| 470 |
+
plt.ylabel(r'$Y$')
|
| 471 |
+
plt.legend()
|
| 472 |
+
|
| 473 |
+
def performance(self,c=0.4) -> dict:
|
| 474 |
+
"""RCI performnace. APE errors.
|
| 475 |
+
Args:
|
| 476 |
+
c (float, optional): correction constant to mitigate division by 0 error. Defaults to 0.4.
|
| 477 |
+
Returns:
|
| 478 |
+
dict: {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 479 |
+
"""
|
| 480 |
+
a=[]
|
| 481 |
+
for i in range(1000):
|
| 482 |
+
dfcopy = (self.df.iloc[:,1:8]-self.df.iloc[:,1:8].min())/(self.df.iloc[:,1:8].max()-self.df.iloc[:,1:8].min())
|
| 483 |
+
a.append(100-abs(np.mean(dfcopy.iloc[1:24,1:].values-dfcopy.iloc[24:,1:].sample(23).values)/(dfcopy.iloc[1:24,1:].values+c))*100)
|
| 484 |
+
gen_acc = np.mean(a)
|
| 485 |
+
|
| 486 |
+
ape = (100-abs(np.mean(self.preds-self.Y.numpy())*100))
|
| 487 |
+
abs_ape = ape*gen_acc/100
|
| 488 |
+
return {'Generator_Accuracy, %':np.mean(a),'APE_abs, %':abs_ape,'Model_APE, %': ape}
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
|
nets/opti/__init__.py
ADDED
|
File without changes
|